
Chi è familiare con i servizi che i Service Provider offrono sulle loro reti IP+MPLS, saprà che tra questi uno dei più interessanti è il servizio VPLS (Virtual Private LAN Service), che è un servizio di tipo Multipoint-to-Multipoint che consente l’emulazione di LAN Ethernet su una rete IP + MPLS. Nella prossima sezione richiamerò alcuni concetti base su questo servizio, necessari per inquadrare bene il problema del nuovo standard oggetto di questo post.
Il servizio VPLS così come è implementato oggi, ha vari difetti che ne impediscono l’utilizzo in scenari avanzati e oggi di forte interesse, come ad esempio l’interconnessione di Data Center (servizio spesso indicato con l’acronimo DCI, Data Center Interconnection). Per questo è stato sviluppato un nuovo modello per l’offerta del servizio VPLS, noto come EVPN (Ethernet VPN), il cui obiettivo è quello di rendere il servizio VPLS più adatto a rispondere alle esigenze del DCI.
Faccio notare che ho parlato di un nuovo modello e non di un nuovo servizio. Il servizio rimane concettualmente identico al servizio VPLS, l’emulazione di LAN Ethernet su una rete IP + MPLS, cambia solo il modo con cui viene realizzato.
Il modello EVPN è stato standardizzato nel Febbraio 2015 nella RFC 7432 - BGP MPLS-Based Ethernet VPN. Il titolo della RFC già da una indicazione dell’idea di base: utilizzare il BGP per annunciare gli indirizzi MAC, con lo stesso modello di funzionamento delle L3VPN. In altre parole, il MAC learning non avviene esclusivamente sul piano dati come nel servizio VPLS, ma avviene parte sul piano dati (MAC learning locale) e parte sul piano di controllo, utilizzando per l’appunto il BGP. Non fatevi ingannare dal fatto che anche il servizio VPLS può utilizzare il BGP nel suo funzionamento (vedi sotto la sezione dedicata ai richiami sul servizio VPLS), il modello EVPN utilizza il BGP in modo molto diverso (coincidente per quanto riguarda la parte di auto-discovery, completamente diverso per quanto riguarda la segnalazione).
Non è solo questa però la novità introdotta dal modello EVPN. Lo standard pone particolare cura nell’implementazione dei collegamenti multi-homing, del load balancing, della prevenzione dei loop, e altro che illustrerò, aspetti non trattati o trattati solo marginalmente nel servizio VPLS. La RFC 7432 ha introdotto molte soluzioni ingegnose per trattare questi aspetti. Raramente mi è capitato di vedere una RFC scritta così bene e con una così puntuale attenzione ai dettagli.
Prima di parlare del nuovo modello EVPN però, come ho detto sopra, è necessario un piccolo “amarcord” sul servizio VPLS. Ma ancor prima di questo però devo confessarvi che non amo questo servizio (l'emulazione di LAN Ethenet, o anche L2VPN), non ne capisco molto il razionale, rispetto a un classico servizio L3VPN. Però per il modello EVPN faccio un'eccezione, per due motivi: il primo che è uno standard molto ben fatto, il secondo che il modello EVPN può essere utilizzato come piano di controllo per tipi di modelli utilizzati nell'Overlay Virtual Networking, come ad esempio le VXLAN trattate nel post precedente.
DUE PAROLE SUL SERVIZIO VPLS
Da un punto di vista logico, il servizio VPLS può essere visto come un servizio che consente di emulare switch Ethernet. Ad esempio, collegare N router dispersi geograficamente con un servizio VPLS equivale a collegare i router localmente a un switch Ethernet con cavi straight-through.
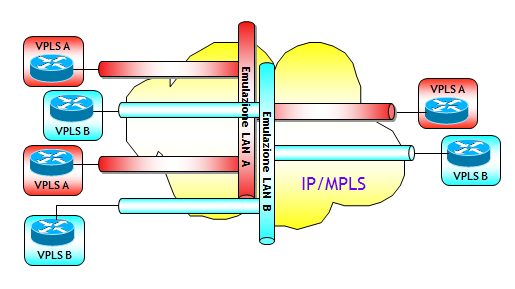
I CE (Customer Edge, ossia i dispositivi del Cliente che si interfacciano alla rete del Service Provider), possono essere un qualsiasi dispositivo che genera trame Ethernet tagged e/o untagged (router o switch Ethernet o Host), e il collegamento tra CE e i router della rete dell’ISP (router PE) può essere in qualsiasi tecnologia (es. Ethernet back-to-back, Ethernet over SONET/SDH utilizzando l’incapsulamento GFP, Ethernet over ATM utilizzando AAL5 (RFC 2684), ecc. ).
Il modello di servizio assomiglia molto al classico servizio L3VPN su reti IP + MPLS, con la sostanziale differenza che tra i siti L3VPN vengono trasportati pacchetti IP e la rete dell’ISP partecipa al routing inter-sito, mentre tra siti VPLS vengono scambiate trame Ethernet (tagged o untagged). Ciò consente in teoria di scambiare anche pacchetti di Livello 3 che non siano IP, anche se questo in realtà non è considerato più un vantaggio importante delle VPLS, poiché ormai tutte le applicazioni si poggiano sull’architettura TCP/IP.
Dal punto di vista fisico, il modello di funzionamento è simile a quello delle L3VPN, con alcune differenze sostanziali. Per ciascun Cliente, vengono create sui PE dove sono attestati i siti, delle istanze L2 Ethernet virtuali dette VSI (Virtual Switch Interface). Ciascuna VSI può essere vista come un insieme di due elementi: una MAC table (di solito indicata come VFI, Virtual Forwarding Instance), e un insieme di interfacce Ethernet fisiche o logiche che formano un dominio broadcast (di solito indicato come Bridge Domain). Le interfacce di accesso dei CE sui PE (attachment circuit) vengono associate alla VSI appropriata via configurazione. Le VSI devono emulare tutte le funzioni degli switch Ethernet:
- Flooding : inviare a tutte le altre VSI della stessa VPLS le trame con indirizzi MAC destinazione Broadcast, o Multicast o Unicast ma sconosciuti (il cosiddetto traffico BUM, Broadcast-Unknown-Multicast).
- MAC Address learning : creare automaticamente le associazioni < MAC , Porta >.
- MAC Address limiting : porre un limite al numero delle associazioni < MAC , Porta > presenti in una VFI.
- MAC Address aging : assegnare un tempo di vita a ciascun entry nella VFI.
- Loop prevention : evitare il fenomeno dei Broadcast Storm. Ricordiamo che nelle reti switched Ethernet, questa funzione è svolta dal protocollo Spanning Tree.
- Forwarding : utilizzo degli entry creati per inoltrare traffico LAN/VLAN.
Per ciascuna VPLS, viene realizzata una maglia completa di pseudowire tra i PE dove sono attestati i siti della VPLS (NOTA: uno pseudowire emula un collegamento punto-punto all’interno del quale è possibile trasportare trame di Livello 2 qualsiasi, in questo caso trame Ethernet). Il perché vi sia bisogno di una maglia completa di pseudowire è legato al trasporto del traffico BUM.
A differenza delle VRF nelle L3VPN, che vengono popolate dal piano di controllo attraverso sessioni MP-iBGP, le VSI vengono popolate dal piano dati attraverso un classico processo di MAC learning. Quando un indirizzo MAC è appreso da un CE locale, la VSI crea un entry che mette in relazione l’indirizzo MAC con la porta dove è attestato il CE. Quando invece l’indirizzo MAC è appreso da un CE remoto, la VSI crea un entry che mette in relazione l’indirizzo MAC con lo pseudowire da dove è stata ricevuta la trama con l’indirizzo MAC come sorgente.

La figura riporta un esempio di contenuto di una VSI. I tre entry presenti sono:
- Il primo relativo all’indirizzo MAC 0024.b14c.c010, che è l’indirizzo MAC dell’interfaccia Ethernet di CE1-A sul collegamento con il PE. La porta corrispondente è la Gi0/2/0/1, che è la porta di accesso di CE1-A sul PE (attachment circuit di CE1-A).
- Il secondo relativo all’indirizzo MAC 0024.a54d.cd20, che è l’indirizzo MAC dell’interfaccia Ethernet di CE2-A sul collegamento con il PE2. Poiché l’indirizzo MAC è stato appreso da una trama ricevuta sullo pseudowire 12, con una VC label annunciata da PE1 a PE2, la porta corrispondente è lo pseudowire 12 verso PE2. Ciò significa che quando il PE1 riceve una trama con indirizzo MAC destinazione 0024.a54d.cd20, inoltrerà la trama sullo pseudowire 12 con la VC label annunciata da PE2 a PE1.
- Il terzo relativo all’indirizzo MAC 0024.de01.1130, che è l’indirizzo MAC dell’interfaccia Ethernet di CE3-A sul collegamento con il PE3. Per questo valgono le stesse considerazioni fatte per il secondo entry, a parte ovviamente il diverso pseudowire utilizzato.
Il Piano di Controllo del servizio VPLS svolge le seguenti due funzioni:
- Discovery.
- Segnalazione degli pseudowire.
Il processo di Discovery consente di determinare quali sono i PE dove sono presenti VSI della stessa VPLS. Un PE ha due modi per scoprire gli altri PE che partecipano alla stessa istanza VPLS:
- Configurazione manuale.
- Processo di Discovery automatico (auto-discovery).
La configurazione manuale è un approccio configuration-intensive, specialmente in presenza di molti PE che partecipano alla stessa istanza VPLS, a causa della necessità di una maglia completa di pseudowire tra i PE. In caso di aggiunta/rimozione di PE è necessario variare la configurazione su tutti i PE.
Con il processo di auto-discovery, ogni PE determina automaticamente, mediante un qualsiasi protocollo, quali sono gli altri PE che partecipano alla stessa istanza VPLS. Per il Piano di controllo delle VPLS, IETF ha definito due standard alternativi:
- RFC 4761 - Virtual Private LAN Service (VPLS) Using BGP for Auto-Discovery and Signaling: utilizza per entrambe le funzioni, discovery e segnalazione degli pseudowire, il protocollo BGP.
- RFC 4762 - Virtual Private LAN Service (VPLS) Using Label Distribution Protocol (LDP) Signaling: utilizza il procollo LDP per la segnalazione, ma lascia completa libertà sull’utilizzo del protocollo per l’auto-discovery (BGP, server RADIUS, ecc.).
È possibile anche utilizzare soluzioni miste. Ad esempio, le recenti versioni dell’IOS/IOS XE/IOS XR Cisco supportano l’utilizzo del BGP sia per l’auto-discovery che per la segnalazione, ma è anche possibile una soluzione mista come l’utilizzo del BGP per l’auto-discovery e LDP per la segnalazione.
Il piano dati segue il classico schema utilizzato dagli switch Ethernet, ossia, il processo di forwarding delle trame Ethernet è basato sull’indirizzo MAC destinazione delle trama ricevute. Quando un PE riceve una trama Ethernet da un CE, analizza l’indirizzo MAC destinazione e utilizza per l’inoltro le informazioni contenute nella VSI associata all’interfaccia di ingresso.
In funzione della presenza o meno nella VSI dell’associazione <indirizzo MAC ; porta>, il PE esegue le seguenti operazioni:
- Se la VSI non ha alcuna associazione <indirizzo MAC ; porta>, la trama viene inviata su tutti i CE locali e remoti della VPLS.
- Viceversa, la trama Ethernet viene inviata sulla porta corrispondente.
La porta destinazione può essere locale, ossia associata ad un altro CE della stessa VPLS che ha il suo accesso sullo stesso PE, oppure remota. In quest’ultimo caso, la porta corrispondente è in realtà uno pseudowire verso un altro PE, dove si trova il CE che ha l’indirizzo MAC destinazione. La figura seguente riporta un esempio di forwarding di una trama Ethernet, generata dal router CE2-A, che ha indirizzo MAC destinazione 0024.b14c.c010.

La trama arriva al router PE2 su una interfaccia associata alla VSI A. La VSI A ha come informazione per l’inoltro, l’invio della trama sullo pseudowire tra PE2 e PE1. La VC label associata allo pseudowire tra PE2 e PE1 è l’etichetta MPLS 72, annunciata da PE1 a PE2 attraverso il protocollo di segnalazione utilizzato (LDP o BGP). La trama Ethernet viene così incapsulata in un pacchetto MPLS con VC label 72. Il pacchetto MPLS così formato viene inoltrato nel LSP MPLS che congiunge PE2 a PE1. Il pacchetto MPLS viaggerà quindi con due etichette, la VC label (etichetta interna), e la PSN label (etichetta esterna). Il pacchetto MPLS arriverà al router PE1 con la sola VC label 72, sulla base della quale verrà effettuato un lookup sulla VSI A. Dal lookup il router PE1 evince che l’indirizzo MAC 0024.b14c.c010 è raggiungibile dalla porta Gi0/2/0/1. Il router PE1 effettua quindi una operazione di label pop, e la trama risultante viene inviata sulla porta Gi0/2/0/1, dalla quale raggiunge il router CE1.
Con i richiami sul servizio VPLS sono costretto a fermarmi qui, altrimenti questo rischierebbe di diventare un post troppo lungo. Chi di voi fosse interessato ad approfondimenti sull’argomento può iscriversi al nostro corso a catalogo IPN273 "MPLS: servizi avanzati", che prevede tra l’altro molte esercitazioni di laboratorio.
LE LIMITAZIONI DEL SERVIZIO VPLS PER IL DCI
La forte richiesta di servizi DCI ha messo a nudo tutte le limitazioni del servizio VPLS. Come citato nella sezione precedente, il servizio VPLS prevede tre diverse opzioni di implementazione:
- Segnalazione LDP e discovery manuale(RFC 4762).
- Segnalazione LDP e auto-discovery via BGP (citata come possibile soluzione nella RFC 4762).
- Segnalazione e auto-discovery via BGP (RFC 4761).
Ognuna di queste opzioni ha i suoi pro e contro. In breve:
- Segnalazione LDP e discovery manuale (RFC 4762): richiede una maglia completa di sessioni LDP multi-hop (dette anche sessioni Targeted-LDP, T-LDP), che devono essere stabilite manualmente. Questo pone chiaramente un serio problema di scalabilità per i Service Provider che devono offrire il servizio a decine/centinaia di migliaia di Clienti, con ciascuna VPLS costituita potenzialmente da un elevato numero di siti. Il modello gerarchico H-VPLS consente di alleviare questi problemi di scalabilità, spostando però il problema sul piano dati dei router PE (problema noto come MAC explosion).
- Segnalazione LDP e auto-discovery via BGP: questa opzione risolve il problema della configurazione manuale dei neighbor LDP, al prezzo però di introdurre in rete un nuovo protocollo, il BGP, utilizzato in questo contesto per la sola funzione di auto-discovery. La segnalazione avviene sempre attraverso una maglia completa di sessioni T-LDP tra PE.
- Segnalazione e auto-discovery via BGP (RFC 4761): questa opzione è la più scalabile poiché non richiede la necessità della configurazione manuale dei neighbor LDP e riduce l’overhead di segnalazione, eliminando la necessità di una maglia completa di sessioni T-LDP. Inoltre, utilizzando la ben nota funzionalità di Route Reflection, la scalabilità ne trae un vantaggio fondamentale. Uno svantaggio di questa soluzione è lo spreco di spazio di etichette MPLS utilizzate, causato dal meccanismo del Label block (approfondimenti sempre nel corso IPN273).
La terza opzione è quella oggi preferita nelle applicazioni pratiche nelle reti dei Service Provider, mentre nelle (piccole) reti Enterprise l’opzione preferita è la prima. Però tutte queste opzioni per l’implementazione del servizio VPLS hanno serie limitazioni circa la ridondanza, ottimizzazione del trasporto del traffico BUM, provisioning e semplicità. L’ideale sarebbe una soluzione L2VPN che abbia caratteristiche del tipo:
- Multi-homing con modalità di forwarding active-active e load balancing da/verso i CE. Il servizio VPLS supporta il multi-homing con modalità single-active. Inoltre, il problema del load balancing non è affrontato.
- Trasporto ottimo del traffico BUM. L’implementazione attuale delle VPLS prevede o ingress replication, o nelle implementazioni più avanzate, LSP MPLS di tipo P2MP. Nessuna implementazione corrente prevede l’utilizzo dei più efficienti LSP MPLS di tipo MP2MP (vedi post precedente).
- Provisioning semplice. Una soluzione ideale dovrebbe prevedere non solo l’auto-discovery dei PE dove sono attivi siti della stessa istanza VPN, simile all’auto-discovery via BGP nelle VPLS, ma anche l’auto-discovery dei PE multi-homed e l’elezione automatica dei Designated Forwarder, ossia dei PE multi-homed responsabili di inviare ai CE il traffico BUM (maggiori dettagli su questo nel seguito).
- Scalabilità mediante l’utilizzo della funzionalità di Route Reflection.
- Convergenza veloce. Una soluzione ideale dovrebbe fornire un modello del tipo MAC independent convergence (vi ricorda qualcosa legato alla convergenza del BGP ?) e l’abilità di gestire in modo efficiente scenari di fuori servizio di collegamenti PE-CE e di un intero PE.
- Eliminazione, o almeno riduzione, del (perverso) meccanismo del flooding. Una soluzione ideale dovrebbe minimizzare le trame broadcast e dare la possibilità all’operatore di scegliere se scartare o effettuare flooding delle trame con indirizzo MAC destinazione non noto.
- MAC mobility. È possibile che un dato host (fisico/virtuale), definito dal suo indirizzo MAC debba essere spostato da un segmento Ethernet a un altro (MAC mobility). Il modello dovrebbe gestire questo problema nel modo più efficiente possibile, riducendo al minimo la segnalazione necessaria ed evitando routing improprio del traffico.
Il nuovo modello EVPN cerca di implementare questo modello ideale (per ulteriori informazioni sui requisiti del modello EVPN vedi la RFC 7209 - Requirements for Ethernet VPN (EVPN), Maggio 2014).
UN PO’ DI TERMINOLOGIA
Prima di vedere le caratteristiche del modello EVPN è necessario introdurre un po’ di terminologia:
- EVI (EVPN Instance): è una istanza EVPN definita su più PE (analogo di una istanza VPLS).
- MAC-VRF: è una tabella MAC su un PE per una determinata EVI (analogo del concetto di Virtual Forwarding Instance nelle VPLS). Per chi è familiare con i classici servizi L3VPN su reti IP+MPLS, è il concetto analogo alle VRF (la ovvia differenza è che le VRF di una L3VPN contengono informazioni di routing di Livello 3, mentre le MAC-VRF contengono informazioni per il switching di Livello 2).
- ES (Ethernet Segment): è l’insieme dei collegamenti presenti tra CE e PE. Nel caso di collegamento multi-homed di un CE a due o più PE, rappresenta l’insieme dei collegamenti. Nel caso di collegamento single-homed a un solo PE, rappresenta l’unico collegamento.
- ESI (Ethernet Segment Identifier): è un identificativo non nullo per l’insieme dei collegamenti tra un CE multi-homed a due o più PE. Nel caso di collegamento PE-CE single-homed, ESI = 0.
- Ethernet tag: è un identificativo di un dominio broadcast (es. una VLAN). Una EVI consiste di uno o più domini broadcast. I valori di Ethernet tag assegnati ai domini broadcast di una data EVI sono assegnati dal service provider.
- Modalità di ridondanza single-active: modalità per cui in un collegamento multi-homed, un collegamento solo viene utilizzato per il forwarding del traffico da/verso un PE. Gli altri sono in “riserva fredda”.
- Modalità di ridondanza active-active: modalità per cui in un collegamento multi-homed, tutti i collegamenti possono essere utilizzati per il forwarding del traffico da/verso un PE.
LOGICA GENERALE DI FUNZIONAMENTO
La logica di funzionamento del modello EVPN assomiglia per certi versi al modello NG-MVPN trattato in un post precedente. Il funzionamento è basato su un totale disaccoppiamento tra piano di controllo e piano dati, tanto che il piano di controllo EVPN può essere utilizzato come piano di controllo per altre applicazioni, come ad esempio le VXLAN, trattate nel post precedente a questo, e le reti PBB (Provider Backbone Bridge) basate sullo standard IEEE802.1ah, anche noto come MAC-in-MAC. Il processo di standardizzazione per queste applicazioni del piano di controllo EVPN è ancora in corso, ma già ad esempio su alcune piattaforme Cisco sono implementate (es. Nexus serie 9000).
Il piano dati può quindi essere realizzato in qualsiasi tecnologia. Possono essere utilizzate tutte le tipologie viste nel modello NG-MVPN per il traffico BUM, mentre per il traffico unicast è possibile utilizzare MPLS, VLXLAN, NVGRE, ecc. .
Il modello EVPN è basato sul concetto di BGP MAC routing. L’idea è simile a quella delle L3VPN, solo che ad essere annunciati via MP-iBGP non sono i prefissi IP dei siti VPN ma gli indirizzi MAC appresi localmente dai PE (e opzionale, anche gli indirizzi IP degli Host che hanno quel determinato indirizzo MAC). Un’altra idea simile alle L3VPN è la modalità di auto-discovery, che avviene attraverso il classico meccanismo del route-target filtering (NOTA: lo stesso identico meccanismo è utilizzato nelle VPLS che utilizzano l’auto-discovery via BGP).
Come ho già detto sopra, ciò che differenzia e di molto il modello EVPN dalle VPLS è la modalità di MAC learning. E allora fatemi illustrare bene questo concetto. Come nelle VPLS (e anche come avviene nelle L3VPN per i prefissi IP), il MAC learning avviene in due fasi: una locale e una remota.
La fase locale è identica a quella delle VPLS: tramite questa un PE apprende dell’esistenza di indirizzi MAC (e volendo con qualche trucco anche dei corrispondenti indirizzi IP associati) e crea nella propria MAC-VRF un’associazione <MAC ; porta locale>. La fase di apprendimento remoto è invece profondamente diversa. Una volta appreso un indirizzo MAC, questo viene comunicato a tutti gli altri PE della stessa EVI tramite annunci MP-iBGP. Il tutto è riassunto nella figura seguente, dove ho ipotizzato, come avviene sempre nelle applicazioni pratiche, di utilizzare dei Route Reflector per minimizzare il numero di sessioni MP-iBGP.

Gli annunci MP-iBGP sono molto particolari, e in modo analogo a quanto è stato già illustrato nel post sul modello NG-MVPN, sono stati definiti nuovi NLRI e nuove Extended Community BGP, peculiari del modello EVPN. Lo IANA ha definito per questa nuova address-family BGP i codici AFI/SAFI pari a 25 (identico a quello delle VPLS) e 70.
In questo post non darò dettagli sul tipo di nuove NLRI ed Extended Community BGP introdotte, che lascerò per il prossimo post di approfondimento. Solo nell’ultima sezione darò un cenno agli annunci di tipo MAC/IP Advertisement Route, che sono quelli che compaiono nella figura sopra. Piuttosto voglio qui illustrare le problematiche legate ai collegamenti multi-homed e le soluzioni adottate per risolverle.
COLLEGAMENTI CE-PE MULTI-HOMED
La gestione dei collegamenti multi-homed CE-PE pone problemi molto interessanti, che il modello EVPN risolve in modo molto brillante. Un passo preliminare alla soluzione dei problemi che seguono è, come fanno i router PE a scoprire di essere sullo stesso ES, ossia in altre parole, come fanno a sapere di essere terminazioni dello stesso collegamento multi-homed ? Bene, questo viene risolto con un semplice annuncio MP-iBGP, contenente uno dei nuovi NLRI, denominato Ethernet Segment Route. I dettagli e il formato di questo nuovo NLRI li illustrerò in un post successivo. Per il momento basta sapere che l’Ethernet Segment Route contiene un campo fondamentale: il valore di ESI assegnato all’ES multi-homed (via configurazione manuale o con qualche criterio automatico). Inoltre, l’Ethernet Segment Route contiene un nuovo Route Target (ES-import Route Target), che viene utilizzato per filtrare annunci MP-iBGP. La regola seguita è molto semplice (vedi figura seguente): un PE parte della stessa EVI, che accetta (tramite filtraggio basato sull’ES-import Route Target) un annuncio MP-iBGP contenente un NLRI Ethernet Segment Route, che contiene un valore di ESI coincidente con quello di un ES terminato sul PE stesso, sa che l’ES è terminato anche sul PE che ha inviato l’annuncio MP-iBGP.

A questo punto, ogni PE multi-homed conosce tutti gli altri PE multi-homed all’ES identificato da un determinato ESI.
E ora vediamo i problemi legati alla gestione dei collegamenti multi-homed. Per ciascuno darò una descrizione del problema e la soluzione prevista.
Duplicazione delle trame BUM
Problema: come è possibile che trame BUM non arrivino duplicate al CE destinazione, quando questo ha un collegamento multi-homed verso due o più PE utilizzato in modalità active-active ? Il problema è esemplificato nella figura seguente (per semplicità si considera un collegamento multi-homed minimale a due soli PE).

Dalla figura si evince che, senza prendere opportuni provvedimenti, una trama Ethernet con MAC destinazione BUM (soggetta quindi a flooding) generata da CE1, arriva a PE2-1 e PE2-2, entrambi multi-homed allo stesso ES, e da questi inviata a CE2. CE2 riceverà quindi due copie della trama Ethernet.
Soluzione: la soluzione di questo problema avviene attraverso l’elezione, per ciascun ES, di un Designated Forwarder (DF), ossia di un router che ha l’incarico di trasmettere il traffico BUM (non il traffico unicast !) verso il CE multi-homed. La procedura di elezione, così come la granularità dell’elezione (un DF per EVI, per ES ?) saranno illustrate nel post di approfondimento.
Split Horizon
Problema: come è possibile fare in modo che trame BUM generate da CE su un collegamento verso un PE non-DF, non ritornino indietro al CE che le ha generate, quando questo ha un collegamento multi-homed verso due o più PE, utilizzato in modalità active-active ? Il problema è esemplificato nella figura seguente.

CE1 genera una trama Ethernet con MAC destinazione BUM. La trama, ricevuta da PE1-1 (che non è il DF dell’ES) viene inviata a tutti i PE appartenenti alla stessa EVI, tra cui PE1-2 che è il DF dell’ES. PE1-2, in qualità di DF, invia la trama verso CE1. Senza un qualche meccanismo per fermare il loop, la trama verrebbe inviata di nuovo da CE1 a PE1-1 e il fenomeno inizierebbe daccapo.
Soluzione: la soluzione di questo problema avviene attraverso una etichetta MPLS detta ESI label. La ESI label viene annunciata da ogni PE dello stesso ES attraverso un annuncio MP-iBGP di tipo Ethernet A-D per ES (la ESI label è contenuta in una opportuna Extended Community associata all’annuncio). Nella ESI label Extended Community, oltre a una etichetta MPLS che viene utilizzata per lo Split Horizon, è presente una flag il cui valore indica la modalità di funzionamento dell’insieme dei collegamenti (all-active se flag = 0, single-active altrimenti). Ogniqualvolta una trama BUM viene ricevuta da un PE di un ES, questo esegue il flooding della trama inserendo la ESI label (solo sulle trame inviate ai PE dello stesso ES). Quando il DF dell’ES riceve la trama, riconosce la ESI label che ha annunciato e quindi non inoltra la trama sottostante al CE. Ad esempio facendo riferimento alla figura sopra, supponendo che PE1-2 (DF dell’ES) annunci la ESI label = 100, quando PE1-1 riceve una trama BUM da CE1, la inoltra a tutti i PE della stessa EVI. Sulla trama inviata a PE1-2 (e solo su quella) aggiunge la ESI label = 100 (oltre ad altre etichette MPLS che servono per il trasporto). Quando PE1-2 riceve il pacchetto MPLS, poiché questo contiene nella posizione bottom-of-stack (ossia la posizione più interna della pila di etichette MPLS) l’etichetta 100, non inoltra la sottostante trama BUM a CE1.
Anche se non obbligatorio, è consigliabile che anche il DF quando invia una trama BUM ricevuta dal CE, incapsuli la trama con la ESI label, anche se questo non è strettamente necessario. La ragione è che così facendo, si evitano loop transitori in caso di fuori servizio del collegamento tra CE e DF (NOTA: in realtà quanto ho appena illustrato vale nel caso il piano dati preveda per il traffico BUM la replica delle trame (modalità ingress replication). Nel caso più elegante ed efficiente di utilizzo di LSP MPLS P2MP, il funzionamento è leggermente diverso, ma il concetto di base rimane identico).
Aliasing e Backup path
Problema: quando un CE è multi-homed a due o più PE e i due o più collegamenti sono in modalità all-active, è possibile che solo un singolo PE dell’ES “impari” un determinato indirizzo MAC. Questo comporta che i PE remoti ricevano l’annuncio MP-iBGP dell’indirizzo MAC (o della coppia <MAC; IP>) da un solo PE di un ES, anche se l’ES ha più PE. Il problema è che come risultato si ha che i PE remoti non sono in grado di effettuare un load balancing del traffico destinato all’indirizzo MAC su tutti i PE dell’ES. Un problema simile si ha quando l’insieme dei collegamenti opera in modalità single-active. Il problema in questo caso è, come fa un PE remoto a identificare un eventuale PE di backup per il traffico diretto verso l’indirizzo MAC annunciato ?
Soluzione: per questi due problemi, molto simili concettualmente, il modello EVPN ha introdotto i concetti di Aliasing e Backup Path. In entrambi i casi, ogni PE di un ES annuncia, via MP-iBGP, l’ESI dell’ES a cui appartiene. L’annuncio avviene attraverso uno dei nuovi NLRI denominato Ethernet A-D per EVI. L’annuncio contiene il valore dell’ESI e una aliasing label. Ora, sulla base di questa informazione e dell’informazione contenuta nell’annuncio Ethernet A-D per ES, ciascun PE remoto conosce quali sono i PE appartenenti allo stesso ES e quindi può installare nella propria MAC-VRF:
- Nel caso di Aliasing, come Next-Hop tutti i PE disponibili, ossia tutti i PE appartenenti allo stesso ES del PE che ha annunciato il MAC.
- Nel caso di Backup Path, come Next-Hop primario il PE che ha annunciato il MAC, come Next-Hop alternativo uno qualsiasi degli altri, scelto con qualche criterio.
Le due figure seguenti riassumono l’idea.


Nella prima è descritto il concetto di aliasing. Si noti l’utilizzo delle etichette MPLS su PE3. Per il traffico unicast verso l’indirizzo MAC-1, quando l’algoritmo di load balancing sceglie come Next-Hop PE1, viene utilizzata l’etichetta MPLS annunciata insieme all’indirizzo MAC (nella figura, pari a L1). Quando invece quando l’algoritmo di load balancing sceglie come Next-Hop PE2, viene utilizzata l’etichetta MPLS annunciata insieme all’Ethernet A-D per EVI (aliasing label, nella figura La2).
Nella seconda figura è descritto il concetto di Backup Path. Le uniche differenze con la prima sono che i due Next-Hop disponibili non sono utilizzati in load balancing, ma in modalità Primario/Backup (nella figura il Next-Hop primario è PE1) e che l’etichetta MPLS utilizzata dal PE di uscita (PE1) è sempre quella annunciata insieme all’indirizzo MAC.
Fast Convergence
Problema: nel modello EVPN, per annunciare gli indirizzi MAC appresi localmente i PE utilizzano annunci MP-iBGP (del tipo MAC/IP Advertisement Route, vedi ultima sezione). In un ambiente dove gli indirizzi MAC sono molti (ad esempio dell’ordine delle centinaia di migliaia se non di più, nel DCI), in assenza di un qualche meccanismo “veloce” di convergenza indipendente dal numero di indirizzi MAC, i tempi di convergenza diverrebbero molto lenti.
Soluzione: la soluzione a questo problema in realtà non è nuova, ne ho già parlato sui post relativi alla convergenza BGP e la soluzione illustrata era il BGP PIC (BGP Prefix Independent Convergence). Bene, qui la soluzione è concettualmente identica. In caso di fuori servizio di un collegamento appartenente ad un determinato ES, l’idea è quella di ritirare non i singoli indirizzi MAC uno per uno annunciati in precedenza, ma l’annuncio MP-iBGP del tipo Ethernet A-D per ES, inviato in precedenza per risolvere il problema dello Split Horizon. Così facendo, ogni entry delle MAC-VRF sui PE che ha come Next-Hop il PE che ritira l’annuncio MP-iBGP del tipo Ethernet A-D per ES, viene invalidato, portando a una convergenza immediata verso il Next-Hop alternativo. Niente di nuovo rispetto a quanto visto con il BGP in passato, cambia solo il contesto.
La soluzione al problema della convergenza veloce è esemplificata nelle figure seguenti.


Come si può notare sulla seconda figura, a fronte di un fuori servizio del collegamento CE1-PE1, PE1 invia agli altri PE della stessa EVI un messaggio BGP UPDATE per ritirare l’annuncio MP-iBGP del tipo Ethernet A-D per ES inviato in precedenza, corrispondente al valore di ESI = ES1. Alla ricezione di questo messaggio, il router PE3 invalida il Next-Hop PE1 e converge immediatamente sul Next-Hop alternativo PE2. Cosa accade invece se ad andare fuori servizio fosse il router PE1 ? Bene, non ve lo dico, (ri)leggetevi il documento sulla convergenza del BGP, la risposta è lì.
ANNUNCI MP-iBGP MAC/IP ADVERTISEMENT
Per chiudere questo primo post sul modello EVPN, voglio dare un cenno alla struttura degli annunci di tipo MAC/IP Advertisement, mediante i quali vengono annunciati sul piano di controllo, gli indirizzi MAC e opzionale, anche indirizzi IP (v4/v6) associati.
Come già detto nella sezione sulla logica del funzionamento del modello EVPN, un PE “impara” i MAC dietro ai CE connessi, attraverso un classico processo di MAC learning locale. Il modo con cui avviene il MAC learning locale è ininfluente. Una volta imparato localmente un indirizzo MAC, un PE lo annuncia a tutti i PE della stessa EVI attraverso un messaggio MP-iBGP UPDATE con NLRI di tipo MAC/IP Advertisement, il cui formato è riportato nella figura seguente (tratta dalla RFC 7432).

Il significato dei vari campi è il seguente:
- RD (Route Distinguisher): campo di 8 byte il cui significato e utilizzo è identico a quello delle L3VPN.
- Ethernet Segment Identifier: contiene il valore di ESI dell’ES da dove l’indirizzo MAC è stato appreso localmente.
- Ethernet Tag ID: valore, assegnato dal Service Provider, che identifica un dominio di broadcast.
- MAC Address Length: è la lunghezza in bit dell’indirizzo MAC. Assume il (classico) valore 48. Valori diversi da 48 non sono (al momento) possibili.
- MAC Address: contiene il valore dell’indirizzo MAC.
- IP Address Length: è la lunghezza in bit di un indirizzo IP associato all’indirizzo MAC. Sono possibili i soli valori 32 per indirizzi IPv4 e 128 per indirizzi IPv6. Il valore 0 indica che il campo successivo non è presente.
- IP Address: contiene il valore di un indirizzo IP associato all’indirizzo MAC. La lunghezza di questo campo può essere 0 (= assenza di indirizzo IP), 4 byte per indirizzi IPv4 e 16 byte per indirizzi IPv6.
- MPLS Label1: contiene, nei 20 bit più significativi, il valore dell’etichetta MPLS associata all’annuncio. Questo valore, analogamente a quanto avviene per L3VPN può essere assegnato per EVI, per indirizzo MAC, oppure sulla base della coppia <ESI; Ethernet Tag ID> (quest’ultimo caso analogo all’assegnazione per CE nelle L3VPN). I vantaggi/svantaggi sono gli stessi.
- MPLS Label2: è un campo opzionale che contiene, nei 20 bit più significativi, il valore dell’etichetta MPLS associata (se presente). Al momento non è utilizzato.
L’aspetto più interessante di questo messaggio, almeno secondo me, è la possibilità di annunciare anche un indirizzo IP associato all’indirizzo MAC. Questo apre la porta a nuovi aspetti di ottimizzazione, come ad esempio la riduzione consistente del flooding dei messaggi ARP (o ND in reti IPv6), del routing inter-VLAN e più in generale di integrazione Livello 2/Livello3. Tutti questi aspetti saranno oggetto di post successivi.
Un PE può imparare gli indirizzi IP associati a un indirizzo MAC in vari modi, ad esempio attraverso ARP/ND snooping, meccanismi di management, o utilizzando un opportuno piano di controllo (NOTA: a un indirizzo MAC possono essere associati più indirizzi IP, ad esempio nel caso di Host dual-stack, un indirizzo IPv4 e uno IPv6). Si noti che è possibile inviare due annunci separati, uno per il solo indirizzo MAC e uno per una coppia <MAC; IP>. Questo è utile in scenari in cui ad esempio l’indirizzo IP è appreso attraverso ARP/ND snooping, e gli entry della ARP cache scadono per timeout. In tal caso la coppia <MAC; IP> viene ritirata, ma l’informazione sull’indirizzo MAC rimane comunque, grazie all’annuncio del solo indirizzo MAC.
CONCLUSIONI
Il modello EVPN sembrerebbe essere molto promettente per applicazioni come l’interconnessione di Data Center e come piano di controllo per funzionalità di Overlay Virtual Network, o integrato con il trasporto MAC-in-MAC. Lo standard è molto sofisticato e molto ben fatto. Un solo post non è certamente sufficiente per trattarlo a fondo. A questo ne seguiranno altri di approfondimento e di integrazione con funzionalità come le VXLAN trattate nel post precedente.
Questo modello, attenzione, al momento non sta solo nelle slide, nei documenti IETF o nelle chiacchiere del sottoscritto, ma è già implementato in varie piattaforme commerciali (es. Cisco ASR 9k, Nexus 7k/9k, Juniper MX/EX, Alcatel-Lucent 7750 SR). Cisco implementa già nei suoi Nexus 9k, EVPN come piano di controllo per le VXLAN.
Coming up next... il Capitolo 9 del libro su IS-IS.
Nessun commento:
Posta un commento