
In un post precedente, ho illustrato il nuovo standard VXLAN (RFC 7348), che consente di eliminare molti dei problemi introdotti dal classico concetto di VLAN, ampiamente utilizzato per segmentare logicamente le reti di Livello 2.
Ricordo che l’idea di base delle VXLAN è quella ben nota delle overlay virtual networks, ossia la possibilità di realizzare una rete logica (virtuale) di Livello 2 sopra una rete fisica esistente. La rete fisica esistente (la rete underlay !) è in questo caso una banale rete IP (v4 o v6, non fa differenza), ma potrebbe essere anche un altro tipo di rete.
Ricordo che l’idea di base delle VXLAN è quella ben nota delle overlay virtual networks, ossia la possibilità di realizzare una rete logica (virtuale) di Livello 2 sopra una rete fisica esistente. La rete fisica esistente (la rete underlay !) è in questo caso una banale rete IP (v4 o v6, non fa differenza), ma potrebbe essere anche un altro tipo di rete.
Il problema più importante nell’implementazione delle VXLAN è la determinazione delle mappe MAC-to-VTEP. Nel post precedente introduttivo sulle VXLAN, ho illustrato come il MAC learning, sia locale che remoto, in accordo alle specifiche della RFC 7348, avviene utilizzando esclusivamente il piano dati. Ma questo costringe a introdurre sulla rete IP underlay un protocollo di routing multicast (PIM-SM/SSM o più spesso PIM-BiDir), e come spiegato ampiamente nel post precedente, questo ha i suoi problemi sia in termini di scalabilità che di gestione della rete underlay.
Per questa ragione sono state introdotte soluzioni alternative basate sull'utilizzo di un piano di controllo. È possibile individuare al momento tre fasi di sviluppo delle VXLAN (NOTA: questa storia di dividere l’evoluzione delle VXLAN in tre fasi è strettamente personale; non c’è niente di ufficiale o di standard in questa suddivisione):
- Fase 1: MAC learning interamente sul piano dati con utilizzo di un protocollo di routing multicast sulla rete underlay. E questo lo abbiamo trattato ampiamente, da un punto di vista teorico, nel post precedente. In questo post mi limiterò solo a illustrare un piccolo test di laboratorio per mostrare un esempio reale di applicazione.
- Fase 2: sempre MAC learning sul piano dati, ma senza ricorrere a un protocollo di routing multicast. L’idea è di utilizzare un meccanismo di Head-end replication (Unicast-only VXLAN) per il traffico BUM.
- Fase 3: utilizzare un vero e proprio piano di controllo per annunciare gli indirizzi MAC degli Host (e se possibile anche gli indirizzi IP associati). Questo piano di controllo è in pratica costituito dal BGP, o meglio dalla sua estensione ampiamente vista nel modello EVPN. Utilizzare un piano di controllo riduce notevolmente il problema del flooding e se il piano di controllo è ben fatto, consente di affrontare in modo efficiente eventuali problemi legati al multi-homing e le problematiche di Load Balancing.
In ogni caso, qualsiasi sia la fase di evoluzione delle VXLAN, il MAC learning avviene sempre in due fasi. La prima è di tipo classico, ed è un MAC learning locale. Tramite questo processo l’interfaccia VTEP “impara” quali sono gli indirizzi MAC locali, ossia degli Host che sono “direttamente connessi” alla macchina (fisica o virtuale) dove è definita l’interfaccia VTEP. La seconda è quella che utilizza o routing multicast, o Head-end replication, o il piano di controllo BGP EVPN.
VXLAN FASE 1: TEST DI LABORATORIO
L’utilizzo del routing multicast per apprendere le mappe MAC-to-VTEP è stato ampiamente descritto nel post precedente, per cui rimando a quel post per la teoria. Mi limiterò qui a illustrare una piccola prova di laboratorio, eseguita utilizzando tre router (virtuali) Cisco CSR1kv e due router “ordinari” (sempre Cisco, ma avrei potuto utilizzare qualsiasi altra marca). La topologia utilizzata per il test è riportata nella figura seguente.
L’utilizzo del routing multicast per apprendere le mappe MAC-to-VTEP è stato ampiamente descritto nel post precedente, per cui rimando a quel post per la teoria. Mi limiterò qui a illustrare una piccola prova di laboratorio, eseguita utilizzando tre router (virtuali) Cisco CSR1kv e due router “ordinari” (sempre Cisco, ma avrei potuto utilizzare qualsiasi altra marca). La topologia utilizzata per il test è riportata nella figura seguente.

Per chi di voi avesse familiarità con le moderne tecnologie dei Data Center, la topologia utilizzata è un classica topologia di tipo Leaf-and-Spine, con due Spine (i router S1 e S2) e tre Leaf (L1, L2 e L3). I Leaf sono di solito switch multilayer fisici che svolgono il ruolo di switch ToR (Top of Rack). Gli Spine sono invece classici router, che di norma non hanno bisogno di alcunché, se non del routing IP classico e al massimo un po’ di MPLS (comunque non indispensabile). Su questo tipo di architettura e i suoi vantaggi, tornerò in seguito con un post ad hoc. La funzione VTEP è in questo esempio localizzata direttamente nei Leaf, ma potrebbe anche essere integrata negli Hypervisor dei server. In quest'ultimo caso, i Leaf svolgerebbero, al pari degli Spine, solo le semplici funzioni di Livello 3.
Nel test di laboratorio ho utilizzato come Leaf i tre CSR1kv (che utilizzano l’IOS XE) e come Spine due router con IOS classico. Come server ho utilizzato 5 server Linux. Tutto l’ambiente è stato realizzato tramite il software di emulazione Cisco VIRL di un mio studente (regolarmente acquistato !).
La rete underlay utilizza come protocollo di routing unicast IS-IS in area singola, e singolo livello 2 di routing. Sulla rete underlay è stato poi configurato il protocollo di routing multicast PIM-BiDir, utilizzando come metodo di selezione del Rendezvous-Point il Bootstrap Router (che ricordo, è standard). Una nota importante, è necessario implementare il PIM-BiDir, il semplice PIM-SM non è in questa applicazione supportato.
Su questa rete sono state configurate tre VXLAN, aventi rispettivamente VNI 5010, 5020 e 5030. La VXLAN 5030 ha un solo Host (H5), connesso al Leaf L3. L’ho inserito solo per simulare un po’ di inter-VXLAN routing. In una ipotetica applicazione pratica, H5 potrebbe essere un Database a cui possono accedere sia gli Host della VXLAN 5010 che quelli della VXLAN 5020. Le tre VXLAN 5010, 5020 e 5030 utilizzano per il traffico BUM rispettivamente i tre gruppi multicast 228.1.1.10, 228.1.1.20 e 228.1.1.30.
Per brevità riporto di seguito le configurazioni rilevanti del Leaf L1, lato Host. Le altre configurazioni, tra cui anche quelle dei Leaf lato rete underlay e dei due Spine, sono in un file testo che potete scaricare a questo link.
interface nve 1
no ip address
member vni 5010 mcast-group 228.1.1.10 ! Gruppo multicast associato a VNI 5010
member vni 5020 mcast-group 228.1.1.20 ! Gruppo multicast associato a VNI 5020
source-interface lo0 ! Indirizzo IP sorgente per interfaccia VTEP (= NVE)
no shutdown
exit
!
interface gi4
no ip address
no shutdown
service instance 10 ethernet
encapsulation untagged
exit
exit
!
interface gi5
no ip address
no shutdown
service instance 20 ethernet
encapsulation untagged
exit
exit
!
bridge-domain 10
member gi4 service-instance 10
member vni 5010
exit
!
bridge-domain 20
member gi5 service-instance 20
member vni 5020
exit
!
interface BDI10
ip address 10.1.10.254 255.255.255.0 ! Default-Gateway per VNI 5010
ip router isis
no shutdown
exit
!
interface BDI20
ip address 10.1.20.254 255.255.255.0 ! Default-Gateway per VNI 5020
ip router isis
no shutdown
exit
La configurazione è abbastanza auto-esplicativa per cui lascio gli ulteriori commenti al lettore. Voglio solo mostrare invece il risultato di alcuni comandi di tipo “show” eseguiti su L1.
L1# show nve interface nve1 detail
Interface: nve1, State: Admin Up, Oper Up Encapsulation: Vxlan
source-interface: Loopback0 (primary:192.168.0.1 vrf:0)
Pkts In Bytes In Pkts Out Bytes Out
15 1518 16 1610
L1# show nve vni
Interface VNI Multicast-group VNI state
nve1 5020 228.1.1.20 Up
nve1 5010 228.1.1.10 Up
L1# show nve peers
Interface Peer-IP VNI Peer state
nve1 192.168.0.2 5020 -
nve1 192.168.0.2 5010 -
Il primo comando consente di verificare lo stato dell’interfaccia VTEP, indicata nei router Cisco come “nve” (network virtualization end-point), il tipo di incapsulamento utilizzato, l’indirizzo IP dell’interfaccia VTEP (= 192.168.0.1, coincidente con l’indirizzo IP dell’interfaccia Loopback 0 di L1) e infine il traffico entrante/uscente dall’interfaccia, ossia la quantità di pacchetti che vengono incapsulati con una intestazione VXLAN (riportati nella visualizzazione come “Pkts Out”) e che vengono decapsulati (riportati nella visualizzazione come “Pkts In”).
Il secondo comando “show” mostra i VNI delle VXLAN associati all’interfaccia VTEP e il corrispondente gruppo multicast associato.
Infine, il terzo comando “show” mostra i VXLAN peers, ossia l’indirizzo IP delle interfacce VTEP e delle VNI presenti nel peer. Si noti che per apprendere i VXLAN peers, ci deve essere prima del traffico tra due Host della stessa VXLAN, appartenenti ai due VXLAN peers.
Con il comando “show” seguente invece è possibile vedere come avviene il MAC learning per il “bridge-domain 10”, che corrisponde al segmento VXLAN con VNI 5010. Inizialmente il comando non mostra alcun indirizzo MAC:
L1# show bridge-domain 10
Bridge-domain 10 (2 ports in all)
State: UP Mac learning: Enabled
Aging-Timer: 300 second(s)
GigabitEthernet4 service instance 10
vni 5010
AED MAC address Policy Tag Age Pseudoport
Dopo aver eseguito un “ping 10.1.10.3” verso l’Host H3 appartenente allo stesso segmento VXLAN 5010, si ottiene il seguente risultato:
L1# show bridge-domain 10
Bridge-domain 10 (2 ports in all)
State: UP Mac learning: Enabled
Aging-Timer: 300 second(s)
GigabitEthernet4 service instance 10
vni 5010
AED MAC address Policy Tag Age Pseudoport
0 FA16.3E1C.2D0C forward dynamic 273 nve1.VNI5010, VxLAN ! MAC remoto
src: 192.168.0.1 dst: 192.168.0.2
0 FA16.3EF6.DBCB forward dynamic 272 GigabitEthernet4.EFP10 ! MAC locale
dal quale si evince che L1 ha “imparato” due indirizzi MAC:
- Quello locale di H1 (MAC = FA16.3EF6.DBCB), raggiungibile attraverso la (pseudo-)porta GigabitEthernet4.EFP10 (NOTA: EFP10 indica l’Ethernet Flow Point associato all’istanza di servizio 10).
- Quello remoto di H3 (MAC = FA16.3E1C.2D0C), raggiungibile attraverso la (pseudo-)porta nve1.VNI5010, con incapsulamento VxLAN.
La figura seguente riporta la cattura di un pacchetto VXLAN, analizzato con wireshark. Il pacchetto trasporta uno degli ICMP Echo Request inviati da H1 a H3.

Infine, per completare la prova, ho eseguito un ping da H1, che appartiene al segmento VXLAN 5010, verso l’Host H5, che appartiene invece al segmento VXLAN 5030:
tt@H1:~$ ping 10.1.30.5
PING (10.1.30.5) 56(84) bytes of data.
64 bytes from localhost (10.1.30.5): icmp_seq=1 ttl=64 time=0.032 ms
64 bytes from localhost (10.1.30.5): icmp_seq=2 ttl=64 time=0.072 ms
64 bytes from localhost (10.1.30.5): icmp_seq=3 ttl=64 time=0.054 ms
64 bytes from localhost (10.1.30.5): icmp_seq=4 ttl=64 time=0.056 ms
64 bytes from localhost (10.1.30.5): icmp_seq=5 ttl=64 time=0.083 ms
^C
--- localhost ping statistics ---
5 packets transmitted, 5 received, 0% packet loss, time 3999ms
rtt min/avg/max/mdev = 0.032/0.059/0.083/0.018 ms
Quindi l’inter-VXLAN routing funziona correttamente. Questo grazie alle interfacce (virtuali) BDI configurate sui Leaf, e ai default-gateway configurati sugli Host.
La prova che ho eseguito utilizza come Leaf dei router virtuali CSR1kv, che utilizzano l’IOS XE. Spero presto di poter eseguire lo stesso test utilizzando l’NX-OS (l’IOS dei Nexus ! Ricordo che la linea Nexus costituisce la punta di diamante degli switch multilayer Cisco per i Data center). Purtroppo vi anticipo che i comandi non sono proprio identici, alcuni sono uguali, altri no. E questo, mi dispiace dirlo, è un vezzo molto negativo che ha Cisco, che cambia sovente la struttura dei comandi in funzione del tipo di IOS (provato mai a configurare un protocollo di routing nell’IOS XR ? Stile di configurazione diverso (molto JUNOS-like !) rispetto all’IOS o IOS XE o NX-OS). Il JUNOS da questo punto di vista è molto più intelligente, i comandi sono sempre gli stessi, indipendenti dalla particolare piattaforma. (NOTA: questa mia considerazione personale non deve essere interpretata come un possibile endorsement di uno o dell'altro costruttore)
VXLAN FASE 2 (UNICAST-ONLY VXLAN)
Come detto più volte, essere legati all’utilizzo del routing multicast per il MAC learning è una forte limitazione pratica. La fase successiva nello sviluppo delle VXLAN è stata l’eliminazione del routing multicast e quindi sviluppare una metodologia di MAC learning basata sull’utilizzo del solo routing unicast (per questo spesso chiamata Unicast-only VXLAN).
L’idea in realtà non è nuova. Se tornate indietro con i miei post, parlando del modello EVPN (e anche del modello NG-MVPN), ho citato tra i possibili metodi utilizzabili sul piano dati, di Ingress Replication (talvolta indicato anche come Head-end Replication). Bene, questo metodo, se calato nella realtà delle VXLAN, non è altro che la possibilità di inviare il traffico BUM in modo molto “grezzo” ed inefficiente, replicando in modalità unicast i pacchetti VXLAN, verso tutte le VTEP dove sono attestati Host dello stesso segmento VXLAN.
Il problema a questo punto è quello di restringere l’ambito di destinazione dei pacchetti VXLAN. In teoria è possibile replicare i pacchetti VXLAN verso tutte le VTEP conosciute, anche quelle dove non sono attestati Host dello stesso segmento VXLAN. Ma questo porrebbe un serio problema di scalabilità. Nasce così un secondo problema: come fa una VTEP a conoscere gli indirizzi IP delle altre VTEP dove sono attestati Host dello stesso segmento VXLAN ? In altre parole, come fa uno switch a creare una tabella (tabella VXLAN VTEP) dove a ciascun VNI corrispondono gli indirizzi di tutte le interfacce VTEP dove sono attestati Host dello stesso segmento VXLAN identificato dallo stesso VNI ?
Non esiste a mia conoscenza alcun documento che propone un metodo standard per creare questa tabella VXLAN VTEP. Sempre a mia conoscenza, l’utilizzo dell’Ingress Replication per veicolare il traffico VXLAN di tipo BUM è stato implementato solo nello switch virtuale Cisco Nexus 1000v. Juniper utilizza (di default) l’Ingress Replication nel modello EVPN, ma questa, benché simile, è un’altra storia.
Giusto per vedere come funziona questo metodo, vi illustro brevemente la sua implementazione nel Cisco Nexus 1000v. A grandi linee ecco cosa accade:
- Quando viene istanziata una nuova macchina virtuale (VM, Virtual Machine), l’Hypervisor notifica la sua presenza al VEM (Virtual Ethernet Module, il modulo software che emula le funzioni del piano dati: forwarding, QoS, sicurezza, ecc.; facendo un confronto con switch fisici multi-chassis, il VEM è l’analogo di una linecard).
- Il modulo VEM aggiunge l’indirizzo MAC della VM locale alla tabella VTEP.
- Il modulo VSM (Virtual Supervisor Module, il modulo software che controlla più VEM come fossero un solo switch logico modulare; facendo un confronto con switch fisici multi-chassis, il VSM è l’analogo della scheda, o delle schede supervisor) aggrega continuamente queste informazioni locali e quindi le invia a tutti i moduli VEM degli altri switch virtuali. Come le invia è un mistero, probabilmente con qualche protocollo proprietario. Dalla documentazione Cisco non si evince molto.
Alla fine di questo processo, ciascun modulo VEM si è costruito le tabelle VXLAN VTEP. Il tutto è riassunto nella figura seguente.

Ora il gioco è semplice. Quando ad esempio il switch virtuale riceve una trama Ethernet di una VXLAN con un determinato VNI, con MAC destinazione BUM, il VEM consulta la tabella VXLAN VTEP, dalla quale apprende tutti gli indirizzi IP (unicast) delle VTEP che hanno Host del segmento VXLAN con lo stesso VNI. Ad esempio, con riferimento alla figura seguente, quando la VM 1, appartenente al segmento VXLAN 1000, genera una trama Ethernet con MAC destinazione BUM, il modulo VEM del switch virtuale consulta la tabella VXLAN VTEP in corrispondenza del VNI 1000, da cui evince gli indirizzi delle VTEP destinazione. Il modulo VEM incapsula quindi la trama Ethernet originale in due pacchetti VXLAN unicast, che vengono inviati separatamente alle VTEP 3.3.3.3 e 4.4.4.4 .
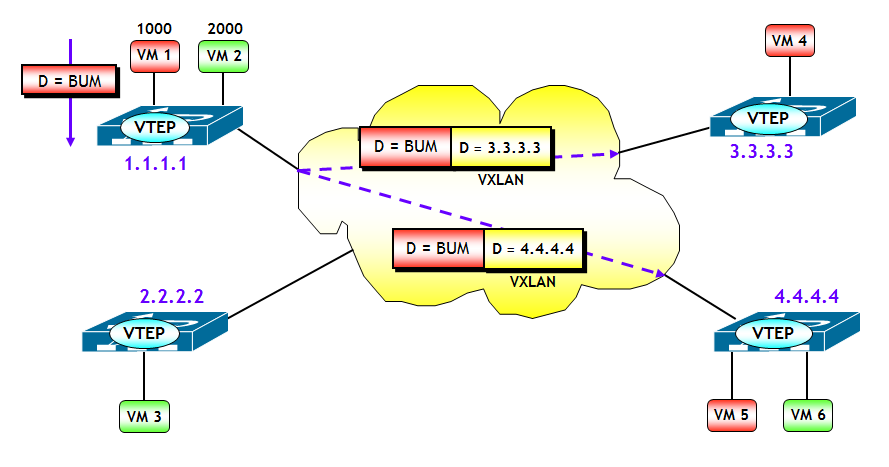
Il metodo Unicast-only VXLAN, a parte il citato caso del Cisco Nexus 1000v (e forse qualche altro che non conosco), non ha riscosso grande successo. In realtà, a ben vedere, è vero che elimina la necessità di un protocollo di routing multicast nella rete underlay, a prezzo però di un notevole aumento del traffico sulla rete, con conseguente spreco di banda. E questo, in un ambiente di tipo cloud dove i tenant (e quindi i segmenti VXLAN) possono tranquillamente essere centinaia di migliaia, potrebbe avere seri problemi di scalabilità. La soluzione migliore sarebbe innanzitutto ridurre il traffico BUM (ad esempio, tramite ARP/ND Proxy, scarto e non flooding dei pacchetti con destinazione sconosciuta). E quel poco che rimane magari inviarlo in unicast con l’Ingress Replication. E qui entra in gioco il modello EVPN !
VXLAN FASE 3: PIANO DI CONTROLLO EVPN
Prima di vedere il funzionamento di VXLAN con piano di controllo EVPN, è opportuno mettere in evidenza quali sono i vantaggi:
- Forte riduzione del traffico BUM, grazie a funzionalità come ARP/ND Proxy e alla possibilità di evitare il flooding delle trame Ethernet con MAC destinazione non noto.
- Gestione molto efficiente della mobilità degli Host.
- Meccanismo di autodiscovery basato sul BGP piuttosto che sul routing multicast.
- Integrazione L2/L3 nativa e possibilità di utilizzare la funzionalità di Distributed IP Anycast Gateway.
- Possibilità di utilizzare tutte le funzionalità avanzate del modello EVPN (accessi multi-homing di tipo active-active, aliasing, fast convergence, split horizon, ecc.).
- Possibilità di creare topologie logiche arbitrarie (es. magliatura completa, Hub-and-Spoke, Extranet, ecc.) grazie a un utilizzo oculato dei Route Target.
Ciò detto, l’integrazione VXLAN/EVPN è trattata in un documento IETF ancora allo stato draft “draft-ietf-bess-evpn-overlay”. In realtà il documento è un po’ più generale, poiché applicabile non solo a un incapsulamento di tipo VXLAN, ma anche NVGRE. VXLAN sta però diventando lo standard adottato da tutti i costruttori di apparati hardware e software, per cui non farò riferimento nel seguito a NVGRE.
L’idea principale dietro l’utilizzo di EVPN come piano di controllo per le VXLAN è quella che ormai ho ripetuto più volte: la netta separazione tra piano di controllo e piano dati insita nel modello EVPN. Come detto nel post precedente, questo fa si che EVPN, benché sviluppato inizialmente con un piano dati puramente MPLS, possa essere utilizzato anche con altri tipi di piano dati, tra cui VXLAN, che come noto non utilizza MPLS per il trasporto, ma una comunissima rete IP.
Il ruolo dei PE è giocato dai dispositivi che implementano la funzione VTEP (NOTA: nel draft IETF citato sopra, il punto dove è implementata la funzione VTEP viene genericamente chiamato NVE, Network Virtualization Endpoint. Per semplicità continuerò a utilizzare il termine VTEP, piuttosto che NVE). Questi dispositivi possono essere o del semplice (si fa per dire) software implementato in un Hypervisor di un server (es. Cisco Nexus 1000v, Juniper Contrail, Nuage VSP), oppure dispositivi hardware, tipicamente switch multilayer utilizzati nei Data Center come switch ToR (es. Cisco Nexus 9k, Juniper QFX5100). In funzione del tipo di dispositivo dove risiede la funzione VTEP, vengono utilizzate o tutte o parte delle funzionalità tipiche di EVPN. Ma prima di vedere questo aspetto, voglio illustrare con un semplice esempio, il principio di base dell’integrazione VXLAN/EVPN.
Con riferimento alla figura seguente, il dispositivo dove risiede la funziona VTEP-3 apprende attraverso un classico MAC learning sul piano dati, l’indirizzo MAC-3 dell’Host H3, che appartiene alla VLAN V3, ed eventualmente anche l’indirizzo IP-3. Sulla VTEP-3 è presente una mappa VLAN-->VNI che fa corrispondere alla VLAN V3 il VNI VNI-3. Ora, utilizzando la sessione MP-BGP verso il Route Reflector RR, viene inviato a RR un annuncio BGP EVPN che contiene come informazioni: <MAC-3, IP-3, VNI-3> e nel campo Next-Hop, l’indirizzo IP della VTEP-3. L’annuncio viene propagato dal RR ai vari RR-Client (ossia, gli altri dispositivi dove sono attive altre VTEP), i quali utilizzano le informazioni contenute nell’annuncio per popolare le MAC-VRF associate alla VXLAN VNI-3 (NOTA: come noto in questo processo giocano un ruolo chiave i Route Target, che per brevità non ho illustrato nella figura).

A questo punto, il trasporto del traffico VXLAN da un qualsiasi Host del segmento VXLAN VNI-3 verso H3, segue le regole già viste per il trasporto del traffico VXLAN. Le trame Ethernet originali vengono incapsulate in pacchetti VXLAN e quindi dirette dalla rete IP underlay verso la VTEP-3. Quest’ultima decapsula i pacchetti VXLAN e quindi invia le trame originali verso H3.
All’apparenza tutto semplice, in realtà è così. Però come sempre ci sono dei dettagli da chiarire.
VXLAN + EVPN: ALCUNI DETTAGLI
Le VXLAN utilizzano il valore di VNI per segmentare il traffico dei vari tenant. Il modello EVPN d’altra parte, per risolvere lo stesso problema utilizza il concetto di EVI (Ethernet Virtual Instance). Quando si utilizza il piano di controllo EVPN per le VXLAN, nasce quindi un problema, non presente quando si utilizza il routing multicast o l’Unicast-only VXLAN: quale relazione esiste tra i due metodi di segmentazione ? In realtà un problema analogo lo abbiamo già trattato nel modello EVPN, dove anche lì esistono due metodi di segmentazione, uno basato sulle VLAN del tenant, uno basato sul concetto di EVI.
Sono possibili due opzioni, ciascuna con i suoi pro e contro.
- Opzione 1: singolo segmento VXLAN per EVI. Con questa opzione, ciascun segmento VXLAN, identificato da un VNI, viene mappato a una EVI. Questo corrisponde al servizio VLAN-based del modello EVPN, descritto in questo post. Il vantaggio di questa opzione è la possibilità di utilizzare il classico meccanismo dei Route Target, sia per limitare la quantità di messaggi BGP UPDATE (utilizzando il trucchetto del BGP Constrained Route Distribution; se non lo conoscete nessuna preoccupazione, ho in canna un breve post per descriverlo), che l’insieme delle route importate in una EVI (infatti vengono importate solo le route che hanno il VNI giusto). Lo svantaggio di questa opzione è l’overhead di configurazione per il corretto provisioning di RT e RD, analogamente a quanto avviene per le L3VPN (a meno che non esista un metodo di determinazione automatica di RD e RT !). Si noti che con questa opzione, la tabella MAC-VRF è identificata sul piano di controllo dal valore di RT e sul piano dati dal valore del VNI (NOTA: per fare un paragone, nel modello EVPN classico la tabella MAC-VRF è identificata sul piano di controllo sempre dal valore di RT, mentre sul piano dati dal valore della service label MPLS).
- Opzione 2: più segmenti VXLAN per EVI. Con questa opzione, più segmenti VXLAN, ciascuno identificato da un VNI, vengono mappati a una singola EVI. Questo corrisponde al servizio VLAN-aware Bundle del modello EVPN, descritto in questo post. Il vantaggio di questa opzione è che l’overhead di configurazione è ridotto (meno RD e RT da gestire, anche se questo diventa un non-problema in presenza di un metodo di determinazione automatica di RD e RT). Lo svantaggio per contro è che una EVI potrebbe importare delle route inutilmente, quando non ha Host di un particolare segmento VXLAN parte del bundle. Si noti che con questa opzione, la tabella MAC-VRF è identificata sul piano di controllo dal valore di RT, e la specifica tabella di bridging all’interno della MAC-VRF dalla coppia <RT, Ethernet Tag ID>. Sul piano dati, la specifica tabella di bridging all’interno della MAC-VRF è identificata dal solo valore del VNI (che è più che sufficiente essendo i possibili VNI più di 16 milioni).
Il draft IETF citato sopra definisce una modalità standard per la determinazione automatica dei RT. Se siete curiosi potete guardarla sul draft, ma non è un aspetto importante.
A questo punto dobbiamo affrontare un altro problema. Nel modello EVPN classico, basato sul piano dati MPLS, il PE di uscita sceglie la tabella MAC-VRF da consultare per l’inoltro del traffico verso i CE, sulla base della service label MPLS (o anche l’aliasing label, nel caso di aliasing). Se ci pensate un attimo questo è analogo a quanto avviene nelle VXLAN, dove per inoltrare correttamente il traffico a destinazione, la funzione VTEP (equivalente del PE !) utilizza il VNI. Ma con una differenza fondamentale, mentre le service label MPLS sono locali al PE, ossia hanno validità solo per il PE che le sceglie (e annuncia), i valori di VNI hanno validità globale (NOTA: se ci fate caso questa è in ultima analisi la differenza tra VLAN e L3VPN; entrambi sono metodi di virtualizzazione, solo che il primo utilizza per il forwarding gli indirizzi MAC e i VLAN-ID (che sono globali, ma potrebbero essere “localizzati” utilizzando strumenti di tipo VLAN-ID rewrite), mentre il secondo utilizza indirizzi IP e service label MPLS (che sono locali ai PE)).
Vista l’analogia tra service label MPLS e VNI, quando il modello EVPN viene utilizzato come piano di controllo per le VXLAN, il valore di VNI viene annunciato utilizzando i campi riservati alle etichette MPLS dei vari tipi di NLRI BGP EVPN (Ethernet Auto-discovery Route (per EVI), MAC/IP Advertisement Route e Inclusive Multicast Route). Tra l’altro, così facendo è possibile rendere i VNI locali, se utile, e non necessariamente globali, dando maggiore flessibilità alla costruzione dei segmenti VXLAN (in particolare quando gli Host dello stesso segmento VXLAN si trovano su diversi Data Center).
Inoltre, per indicare il tipo di incapsulamento utilizzato sul piano dati (VXLAN, NVGRE, MPLS, e possibilmente altro), a tutti gli annunci BGP EVPN, di qualsiasi tipo, viene aggiunta la BGP Encapsulation Extended Community definita nella RFC 5512. Il tipo di incapsulamento è identificato da un valore numerico standard (es. VXLAN = 8, NVGRE = 9, MPLS = 10, ecc.).
Infine, aspetto molto importante, il campo Next-Hop dell’attributo MP_REACH_NLRI degli annunci contiene l’indirizzo IP della VTEP da dove parte l’annuncio.
Solo per vostra curiosità, vi riporto il risultato di un comando “show” ottenuto su un switch multilayer Cisco Nexus della serie 9000, che mostra il dettaglio di un annuncio BGP EVPN di tipo MAC/IP Advertisement,con alcuni commenti (NOTA: nella visualizzazione ho omesso alcune parti che riguardano l’inter-VXLAN routing, che illustrerò in un prossimo post).

Come ho già citato, in funzione del tipo di dispositivo dove risiede la funzione VTEP, vengono utilizzate o tutte o parte delle funzionalità tipiche di EVPN. In particolare i casi da valutare sono due:
- La funzione VTEP è svolta via software e localizzata in un Hypervisor (es. KVM, Hyper-V, VMware NSX, ecc.).
- La funzione VTEP è realizzata in hardware e localizzata in un switch ToR.
ASPETTI OPERATIVI: VTEP IN UN HYPERVISOR
Quando, utilizzando la nomenclatura EVPN, PE e CE sono colocati sulla stessa macchina fisica, es. quando un PE, ossia la funzione VTEP, risiede in un server e i CE sono delle VM (Virtual Machine), i collegamenti PE-CE sono virtuali e tipicamente non sono multi-homed. Il caso pratico più comune di questo scenario si ha quando la funzione VTEP risiede in un Hypervisor.

In questo scenario, tutte le funzionalità EVPN legate al multi-homing (es. split horizon, aliasing, fast convergence, elezione del DF) non sono necessarie. Questo riduce quindi l’insieme dei tipi di annunci BGP EVPN e delle nuove Extended Community, necessari al funzionamento. In particolare, sono utilizzate solo i NLRI di tipo 2 (MAC/IP Advertisement Route) e tipo 3 (Inclusive Multicast Route), e le Extended Community MAC Mobility e Default Gateway. Attenzione però, per fare in modo che i PE che risiedono in Hypervisor possano interagire con PE che hanno CE multi-homed, questi devono essere comunque in grado di trattare tutto l’insieme degli annunci BGP EVPN e tutte le Extended Community.
In questo scenario, le procedure EVPN necessarie si riducono a:
- MAC learning locale degli indirizzi MAC delle VM.
- Annuncio degli indirizzi MAC delle VM attraverso MAC/IP Advertisement Route.
- MAC learning remoto degli indirizzi MAC.
- Scoperta delle altre VTEP e costruzione del piano dati per il trasporto del traffico BUM, attraverso Inclusive Multicast Route.
- Gestione della mobilità delle VM (MAC mobility).
Lo scenario di VTEP che risiedono in un Hypervisor richiede quindi una versione semplificata delle funzionalità EVPN. Vorrei farvi notare infine, che in questo scenario, i switch ToR dove sono connessi i server (tipicamente con collegamenti multi-homed), sono parte integrante della rete underlay, ossia possono essere considerati come dei semplici router della rete underlay.
ASPETTI OPERATIVI: VTEP IN UN SWITCH ToR
Lo scenario in cui invece la funzione VTEP risiede in un switch ToR è molto più complesso e richiede tutte le funzionalità avanzate del modello EVPN. Questo perché i server, che in questo scenario sono i CE, hanno normalmente collegamenti dual-homed verso due switch ToR.

In questo scenario, sono necessarie tutte le funzionalità EVPN legate al multi-homing, e quindi tutto l’armamentario degli annunci BGP EVPN e le nuove Extended Community. Però, il lettore attento avrà notato che bisogna apportare alcune piccole modifiche al funzionamento di EVPN. Infatti, tra le varie funzionalità di gestione dei collegamenti multi-homed nel modello EVPN, ve ne sono due che utilizzano delle etichette MPLS: lo split horizon e l’aliasing, che utilizzano rispettivamente la split horizon label (annunciata attraverso la ESI label Extended Community inserita negli Ethernet AD per ES) e l’aliasing label (inserita nel campo MPLS Label degli annunci Ethernet AD per EVI). Ora, quando si utilizza come piano dati VXLAN, la rete underlay è una pura e semplice rete IP, che quindi non è in grado di gestire etichette MPLS.
La soluzione al problema è però abbastanza semplice. Ad esempio, per lo split horizon è sufficiente utilizzare sui PE che ricevono traffico BUM da un altro PE, la seguente regola (un po’ più laboriosa):
- Determinare l’indirizzo IP sorgente della VTEP che ha inviato la trama BUM.
- Consultare la tabella degli annunci BGP EVPN di tipo 4 ricevuti da questo indirizzo IP.
- Se tra gli annunci di tipo 4 inviati dalla stessa VTEP del punto 1, ve ne è uno con ESI identico a quello configurato sul PE, allora la trama BUM viene scartata.
Per quanto riguarda l’aliasing, il funzionamento è analogo al caso delle etichette MPLS, con la differenza che il load balancing è basato sugli indirizzi IP delle VTEP destinazione appartenenti allo stesso segmento Ethernet, senza utilizzare etichette MPLS.
Bene, con questo ho concluso. In realtà manca di affrontare il problema dell’inter-VXLAN routing con le modalità simmetrica e asimmetrica, ma lascio questo argomento per un prossimo post.
CONCLUSIONI
In questo post ho mostrato l’evoluzione del piano di controllo delle VXLAN. Si è passati da una proposta iniziale di un non-piano di controllo (RFC 7348), dove il MAC learning avviene esclusivamente sul piano dati, utilizzando il routing multicast nella rete IP underlay, a una soluzione intermedia con un mezzo piano di controllo (quello che serve a creare le tabelle VXLAN VTEP) e che utilizza Ingress Replication per il traffico BUM (Unicast-only VXLAN), infine al più sofisticato ma molto più efficiente piano di controllo EVPN.
Quest’ultima soluzione è già implementata in apparati molto utilizzati nei Data Center, come ad esempio i più volte citati Cisco Nexus 9k e Juniper QFX5100.
Ricordo comunque che in tutte le varie soluzioni, il MAC learning locale rimane (mi chiedo, ma non sarebbe più semplice comunicare immediatamente con qualche diavoleria simil-annuncio di un protocollo di routing, quale è l’indirizzo MAC della VM alla sua accensione, senza attendere l’invio della prima trama Ethernet (un po’ come avveniva nel vecchio ES-IS ...) ? Sarebbe tutto più semplice e più veloce, e si potrebbe tranquillamente evitare il flooding delle trame con indirizzo MAC sconosciuto (e questo vi fa capire come all’origine di tutti i problemi delle reti switched Ethernet vi sia il concetto di flooding ! Se ci riflettete un attimo, tutti i problemi nascono da lì. Che poi in ultima analisi questa è la vera differenza tra il forwarding a Livello 2 e Livello 3 di trame/pacchetti con destinazione ignota: il Livello 2 fa flooding, il Livello 3 scarta)).
Ma questo pone un problema ben più complesso: ma se dotiamo il Livello 2 Ethernet di un piano di controllo, aggiungendo a EVPN anche un piano di controllo Host-Switch, che differenza (concettuale) ci sarebbe tra Livello 2 e Livello 3 ? Nessuna, e quindi uno dei due è ridondante e andrebbe eliminato. Quale ? Io non avrei dubbi ... (e pian piano ci si arriverà, tranquilli, è solo questione di tempo; intanto lo Spanning Tree è defunto (anche Radja Perlman, quella che lo inventato si è pentita !), il MAC learning rimane solo a livello locale ma prima o poi sparirà, e così via ...).
Il prossimo post: Dalle Reti di Clos ... alle Reti di Clos.
Grazie Tiziano, come sempre riesci ad essere molto semplice e breve nelle spiegazioni, ma molto efficace nel far capire gli argomenti... Grazie per queste perle.
RispondiElimina