
La determinazione dell’albero SPF ha rappresentato in passato il collo di bottiglia nel tempo di convergenza dei protocolli Link-State, considerato l’alto tempo di calcolo necessario per la determinazione dell’albero SPF, tramite l’algoritmo di Dijkstra.
Vari fattori hanno contribuito negli anni a ridurre in modo sostanziale il tempo di calcolo dell’albero SPF, come ad esempio, la maggiore potenza di elaborazione a disposizione dei router, l’ottimizzazione del codice e l’introduzione di metodi che contribuiscono ad evitare il ricalcolo quando in realtà non servirebbe.
Tra i metodi che consentono di evitare inutili ricalcoli dell’algoritmo SPF, illustrerò in questo post l’incremental SPF (iSPF) e il Partial Route Calculation (PRC).
Il metodo iSPF consente di evitare il ricalcolo dell’albero SPF quando la variazione della topologia logica non interessa l’albero SPF originale, mentre il PRC consente di evitare il ricalcolo dell’albero SPF quando la topologia logica della rete rimane invariata.
Grazie a questi metodi, se applicati, il tempo per la determinazione dell’albero dei cammini ottimi subisce una ulteriore sostanziale diminuzione.
INCREMENTAL SPF (iSPF)
L’idea dell’algoritmo iSPF è molto vecchia e fu introdotta per la prima volta nel routing della rete ARPANET nel lontano Marzo 1979. Il metodo e i risultati dell’applicazione furono riportati nell’articolo "ARPANET Routing Algorithm Improvements", di Eric Rosen e altri.
Per comprendere il funzionamento di iSPF, consideriamo dapprima la topologia logica riportata a sinistra nella figura seguente. A destra è riportato l’albero SPF determinato dal router A (di cui il lettore può facilmente verificare la correttezza).

Si noti che l’albero SPF non contiene i link logici (adiacenze !) DC e DG. Ciò significa che la perdita delle adiacenze DC e/o DG, non ha alcun effetto sulla determinazione dell’albero SPF, che rimane esattamente identico, come mostrato nella figura seguente.

La conseguenza pratica è che in caso di perdita delle adiacenze DC e/o DG, il processo di routing non ha alcun bisogno di ricalcolare l’algoritmo SPF. L’eventuale ricalcolo dell’albero SPF produrrebbe esattamente lo stesso albero SPF !
Un altro caso in cui il metodo iSPF consente di risparmiare il ricalcolo dell’intero albero SPF, si ha quando viene aggiunto alla topologia logica un router "foglia" (stub router), ossia un router che ha una singola connessione con un altro router. La figura seguente mostra cosa avviene in una simile situazione.
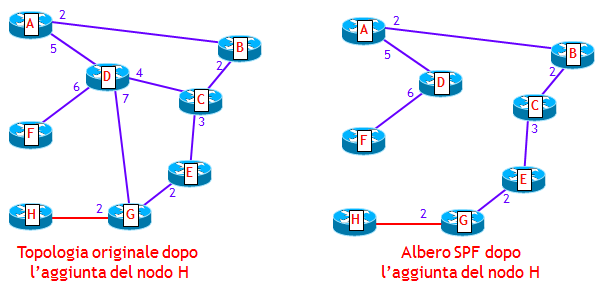
Alla topologia originale viene aggiunto lo stub router H. Il nuovo albero SPF, dopo l’aggiunta dello stub router H, risulta identico al precedente, con la sola variante dell’aggiunta dello stub router H. In altre parole, l’albero SPF è semplicemente "esteso" con l’aggiunta del nuovo stub router. Ciò significa che l’albero SPF, anche in questo caso non va ricalcolato.
Un altro caso in cui il metodo iSPF consente di risparmiare il ricalcolo dell’intero albero SPF, si ha quando viene persa un’adiacenza che è parte dell’albero SPF originale. In questo caso è necessario il ricalcolo di quella sola parte dell’albero SPF che coinvolge tutti i router collegati a valle dell’adiacenza persa. La figura seguente mostra cosa avviene in una simile situazione.

Supponiamo che l’adiacenza tra i router C ed E cada. L’adiacenza è parte dell’albero SPF originale, quindi è necessario un ricalcolo dell’albero SPF. Ma il ricalcolo non coinvolge i router B, C, D e F, ma solo i router G ed E, che sono a valle dell’adiacenza persa. In altre parole, il router A, la radice dell’albero SPF, ricalcola i percorsi ottimi solo verso i router E e G, e non verso gli altri.
Una proprietà interessante di iSPF in questa situazione, è che più l’adiacenza persa è lontana dalla radice dell’albero, meno calcoli vengono effettuati. Sebbene per la radice dell’albero il tempo di rilevazione dell’adiacenza persa aumenti, a causa dell’aumento dei tempi di propagazione (via flooding) dei LSP (o LSU nel linguaggio OSPF), il nodo radice, grazie all’utilizzo di iSPF, esegue meno calcoli, riducendo sostanzialmente il tempo per determinare i nuovi percorsi ottimi.
Si noti comunque che, poiché ciascun router ha un diverso albero SPF per la topologia originale, la perdita di una stessa adiacenza può avere effetti diversi sul guadagno di efficienza di iSPF, rispetto alla determinazione classica dell’albero SPF.
Altro aspetto interessante di iSPF è che la sua efficienza, rispetto alla determinazione classica dell’albero SPF, è tanto maggiore quanto minore la magliatura della rete. Nel caso asintotico di rete completamente magliata, iSPF non da alcun vantaggio.
Questo esempio, e quello riportato nelle due figure precedenti, rendono l’idea del funzionamento del metodo iSPF, che consiste nell’evitare ricalcoli inutili dell’algoritmo di Dijkstra o anche di diminuire il numero di calcoli da effettuare.
IMPLEMENTAZIONE CISCO DI iSPF
Nelle piattaforme di routing Cisco, di default l’iSPF non è abilitato e non sempre è possibile abilitarlo.
Nei router che utilizzano IOS o IOS XE, iSPF per OSPF (e anche per IS-IS) può essere abilitato con il semplice comando "ispf" eseguito a livello di processo di routing. Nell’IOS XR invece, l’implementazione di OSPF non prevede l’abilitazione di iSPF, mentre è possibile per il protocollo IS-IS.
La figura seguente riporta i risultati di un esperimento che mette a confronto l’algoritmo SPF classico e l’iSPF.

Come si può notare, all’aumentare del numero di nodi, il miglioramento introdotto dall’iSPF diventa veramente sensibile. In una rete di 10.000 nodi, si passa da tempi di circa 520 msec per l’algoritmo SPF classico, a circa 50 msec per l’algoritmo iSPF.
PARTIAL ROUTE CALCULATION (PRC)
Il lettore familiare con il protocollo IS-IS sa che un aspetto chiave di IS-IS, è che i prefissi IP sono visti come particolari stub networks (End System nel linguaggio di IS-IS), ossia, direttamente connessi ad un router. Quando un router che utilizza IS-IS invia il suo LSP che descrive la sua «topologia locale», inserisce in questo anche l’elenco dei prefissi IP direttamente connessi (sia IPv4 che eventualmente IPv6, che di altri protocolli, non necessariamente di Livello 3).
Questo ha implicazioni importanti nel calcolo/ricalcolo dei percorsi ottimi. Infatti, per raggiungere un Host di qualsiasi prefisso IP è sufficiente «localizzare» il prefisso, ossia determinare il router dove questo è direttamente connesso, e quindi determinare il percorso ottimo verso questo router. In caso di cambio dello stato (up/down) del prefisso IP, oppure di una variazione della metrica della sua interfaccia, ma non di cambio della topologia di rete, non viene ricalcolato l’intero albero SPF, ma solo identificata l’eventuale presenza su un altro router del prefisso IP, o la sua assenza. Questo comportamento viene indicato come Partial Route Calculation (PRC) ed è alla base della maggiore scalabilità di IS-IS rispetto ad OSPF. Si noti che un ricalcolo dell’intero albero SPF, è necessario solo in caso di cambio di topologia della rete e/o di cambio delle metriche associate ai collegamenti.
La situazione in OSPF (o meglio, in OSPFv2), è un po’ diversa. Infatti in OSPFv2, a fare da trigger per l’esecuzione dell’algoritmo SPF è la ricezione di LSA di tipo 1 e tipo 2, mentre nel caso di ricezione di LSA di tipo 3, 4, 5, 7, il ricalcolo completo non viene eseguito, ma viene eseguito un Partial Route Calculation. Questo perché i LSA di tipo 1 e 2 incorporano sia informazioni topologiche, che informazioni sulle stub network.
Ciò significa che quando una stub network viene annunciata attraverso un LSA di tipo 1 (o tipo 2 nel caso di prefissi di segmenti broadcast con router dove è attivo un processo OSPF), OSPF ricalcola inutilmente l’intero albero SPF. Questo è uno degli aspetti negativi di OSPFv2, che è stato sanato successivamente con OSPFv3, dove, come per IS-IS, vi è un disaccoppiamento totale tra topologia logica della rete e le stub network. Infatti in OSPFv3, le stub network sono annunciate da LSA separati (Intra-Area-Prefix-LSA, LS type = 0x2009), e non più da LSA di tipo 1 o 2, che invece annunciano solo variazioni di topologia.
Tutto ciò, genera in OSPFv2 l’interessante quesito pratico, riportato nella figura seguente: come è meglio annunciare una stub network, tramite LSA di tipo 1 oppure tramite LSA di tipo 5 (o 7 se il router è parte di un’area NSSA) ? (NOTA: le configurazioni della figura sono relative all'IOS XR)

Il problema con il primo approccio è che le stub network annunciate via LSA di tipo 1 comportano un inutile ricalcolo dell’intero albero SPF, mentre se la stessa stub network fosse annunciata attraverso LSA di tipo 5 o 7, verrebbe eseguito un PRC.
Il rovescio della medaglia è, utilizzando LSA di tipo 5, una possibile maggiore occupazione di memoria. Ad esempio, se un router avesse 25 stub network, la dimensione del LSA di tipo 1 aumenterebbe di 300 byte, mentre nel caso di utilizzo del comando "redistribute connected" verrebbero generati 25 LSA di tipo 5, per un totale di 1.100 byte. In realtà, se fosse possibile aggregare i 25 prefissi esterni, o una parte di essi, si potrebbe avere una occupazione di memoria minore.
Nelle reti di piccole dimensioni probabilmente questa alternativa non da luogo a differenze sensibili, per cui quale sia il metodo utilizzato per annunciare le stub network poco importa. In reti di grandi dimensioni invece questo è un altro trade-off da valutare nel progetto complessivo della rete.
NOTA: nel caso particolare in cui le stub network siano interfacce di Loopback, è più conveniente utilizzare il primo metodo. Infatti, poiché queste non vanno mai fuori servizio, non cambiano di stato, e quindi non devono essere mai riannunciate.
CONCLUSIONI
Con questo post, ho illustrato un altro tassello sulle metodiche per ridurre i tempi di convergenza dei protocolli Link-State. Non credo sia questo un aspetto dirimente del problema, perché i tempi di calcolo dell'algoritmo SPF anche in reti di grandi dimensioni vanno via via riducendosi. Però tutto aiuta ...
Il prossimo post su questo argomento sarà sulla funzionalità "spf per-prefix prioritization", ossia sui meccanismi che consentono ai prefissi più importanti di essere trattati con precedenza rispetto a quelli meno importanti (e che quindi finiscono nella RIB e FIB prima di altri prefissi !).
Nessun commento:
Posta un commento