
E' stupefacente che un protocollo come il TCP, nato nel lontano 1973, sia ancora oggi oggetto di studi e ricerche e proposte di miglioramento. Il TCP è il protocollo di trasporto più utilizzato nell'Internet. Si stima che più del 95% del traffico IP mondiale utilizzi a livello di trasporto il TCP, e la percentuale sale addirittura al 99% nei moderni Data Center.
Inizialmente il TCP, il cui acronimo era Transmission Control Program, e non Transmission Control Protocol come è oggi, inglobava sia il livello rete (livello 3) che di trasporto (livello 4). Solo successivamente, con l'avvento dell'architettura di comunicazione a strati ISO/OSI, si decise di enucleare il livello 3 dal TCP e così nacque il protocollo IP, standardizzato nella mitica RFC 791 da Jonathan (Jon) Postel. Anche qui, trovate una biografia scientifica di Jon Postel nella Hall of fame.
Il TCP ha avuto, dopo il 1973, un altro sviluppo fondamentale nel 1988, con l'introduzione del meccanismo di Congestion Control, i cui principi fondamentali furono ideati da Van Jacobson (il suo articolo originale si trova a questo link). Questo meccanismo, standardizzato successivamente da IETF nella RFC 2001 (Gennaio 1997), aggiornata dalle RFC 2581 (Aprile 1999) e RFC 5681 (Settembre 2009), è stato oggetto di vari studi e diverse implementazioni, tra cui TCP Tahoe (la versione originale sviluppata da Van Jacobson), Reno (anche questa si deve a Van Jacobson, è simile a Tahoe con in più il meccanismo di Fast Recovery), Vegas, ecc., fino alla recentissima CUBIC. Il meccanismo fu introdotto dopo che nell'Ottobre 1986 si ebbe il primo "collasso" per congestione dell'Internet (che a quel tempo era un infinitesimo di quella che è oggi !). Questo avvenne in un collegamento tra una delle sedi dell'Università della California a Berkeley e una sede dei Lawrence Berkeley National Laboratory, distanti tra loro poco meno di 400 metri. Un collegamento di 3 hop, a 32 Kbps, con un throughput che crollò alla stratosferica velocità di 40 bps (avete letto bene, 40 bit al secondo !).
In questo post voglio illustrare una variante del TCP, introdotta nel 2010 e adottata in molti Sistemi Operativi (es. Windows Server 2012), che è stata ottimizzata per l'utilizzo in ambito Data Center, e per questo chiamata DCTCP, che sta per Data Center TCP. Per far questo è però necessario che vi ricordi i (soli) principi di funzionamento del TCP Congestion Control e come funziona il meccanismo ECN (Explicit Congestion Notification), specificato nella RFC 3168.
TCP CONGESTION CONTROL: PRINCIPI DI FUNZIONAMENTO
Il TCP ha due tipi di controllo, da non confondere tra loro:
- TCP Flow Control: è basato sul classico meccanismo della Finestra di Ricezione (Receiver Window, indicata con rwnd (utilizzo la notazione della RFC 5681)), e serve a controllare il flusso di byte che una sorgente può inviare a un ricevitore, senza attendere l'arrivo del TCP ACK. Il principio di funzionamento è molto semplice: il ricevitore specifica, attraverso il valore di rwnd espresso in byte, inviato alla sorgente in un campo dell'intestazione TCP (il campo Window, di 16 bit), quanti byte è in grado di accettare. Sulla base di questo valore, la sorgente può inviare rwnd byte al ricevitore, senza bisogno di ricevere alcun TCP ACK.
- TCP Congestion Control: è basato anche questo su un classico meccanismo a finestra (Congestion Window, comunemente indicata come cnwd), ma con due differenze fondamentali: la finestra cnwd è scelta dalla sorgente e non dal ricevitore e inoltre il valore è espresso in multipli del valore SMSS (Sender Maximum Segment Size), definito durante durante la fase di three-way-handshake iniziale. Il valore cnwd viene definito dinamicamente sulla base di un feedback dalla rete, che ne segnali l'eventuale stato di congestione.
Indicando con W la finestra effettivamente utilizzata dalla sorgente, espressa in byte, è ovvio che deve sempre essere:
W = min(cnwd, rwnd)
La differenza fondamentale tra i due tipi di controllo è che il Flow Control non richiede alcun segnale di congestione per il funzionamento: il valore rwnd è scelto direttamente dal ricevitore sulla base dell'occupazione locale delle sue risorse, e non tiene conto in alcun modo di una eventuale congestione della rete di collegamento tra i due estremi della connessione TCP. Viceversa, il meccanismo di TCP Congestion Control richiede, come detto sopra, un segnale di feedback che in qualche modo notifichi l'eventuale stato di congestione della rete. Quale sia questo segnale di congestione lo discuteremo nel seguito. Per il momento supporrò che il segnale di congestione sia o la scadenza del TCP RTO (TCP Retransmission TimeOut), o la ricezione di tre TCP ACK duplicati consecutivi.
Ciò che rende il meccanismo di TCP Congestion Control interessante, è la modalità con cui viene "aperta" o "chiusa" la finestra di congestione. Vi richiamerò i principi di funzionamento, che già comunque dovreste conoscere, anche se repetita iuvant.
Il meccanismo di TCP Congestion Control è basato sulla logica AIMD (Additive Increase/Multiplicative Decrease), che consiste, una volta ricevuto un segnale di congestione di rete, di ridurre velocemente il ritmo di emissione dei segmenti TCP (Multiplicative Decrease), e quindi ritornare più o meno al livello precedente la congestione, in funzione del persistere o meno dello stato di congestione, con un ritmo più blando (Additive Increase).
Focalizziamo per il momento l'attenzione su cosa avviene alla ricezione del segnale di congestione. Il TCP "educatamente" reagisce diminuendo il ritmo di emissione dei segmenti e quindi lo aumenta, all'inizio in modo "aggressivo" (fase di Slow Start) poi in modo più blando (fase di Congestion Avoidance). Per fare questo, il TCP utilizza due variabili, la già citata finestra di congestione cnwd e una soglia SSTHRESH (Slow Start THRESHold), che segna il confine tra la fase di Slow Start e di Congestion Avoidance. A grandi linee questo è ciò che avviene:
Quando cnwd' raggiunge il valore immediatamente inferiore a SSTHRESH, inizia la fase di Congestion Avoidance, dove la crescita di cnwd' diventa più blanda e, per ogni TCP ACK ricevuto segue la legge:
cnwd' <-- cnwd' + 1/cnwd'
Anche qui, è semplice dimostrare che ad ogni RTT la crescita di cnwd' è di tipo lineare:
cnwd' <-- cnwd' +1
La figura seguente riassume quanto fin qui detto.

Quella esposta è la versione originale di Van Jacobson del meccanismo di Congestion Avoidance, nota come TCP Tahoe. Delle altre versioni non parlerò, magari ci ritornerò in seguito con qualche altro post. Per trattare il DCTCP è sufficiente quanto esposto in questa sezione. A questo punto è ora di trattare il secondo argomento propedeutico.
EXPLICIT CONGESTION NOTIFICATION (ECN)
Come visto nella sezione precedente, la regolazione del traffico delle sessioni TCP avviene sulla base di un segnale di congestione "implicito" da parte della rete (es. la scadenza del TCP RTO (TCP Retransmission TimeOut), o la ricezione di tre TCP ACK duplicati consecutivi). Sulla base di questo segnale, il TCP entra nella fase di Slow Start e successivamente nella fase di Congestion Avoidance, riducendo di fatto drasticamente la frequenza di emissione dei segmenti, per poi aumentarla all'inizio in modo aggressivo, poi più gradualmente.
Esiste un algoritmo, il Random Early Detection (RED), che qualcuno chiama anche Random Early Discard o Random Early Drop, implementato da molto tempo nei router di tutti principali vendor, che sfrutta in modo intelligente questa proprietà del TCP, scartando in modo probabilistico pacchetti di applicazioni che utilizzano a livello di trasporto il TCP, al superamento di una prima soglia di guardia. (NOTA: per chi non conoscesse questo algoritmo, a questo link potete scaricare un estratto dalla mia documentazione sulla "QoS IP in ambiente Cisco", dove è tutto spiegato con dovizia di particolari).
Il meccanismo ECN ha lo scopo di migliorare il RED evitando, quando possibile, lo scarto dei pacchetti. L’idea del meccanismo ECN è quella di segnalare esplicitamente alla sorgente, tramite opportuni bit, la congestione di un buffer. Quindi, quando il RED decide, nella regione di scarto aleatorio, di scartare un pacchetto, la presenza del meccanismo ECN fa si che il pacchetto non venga scartato, ma inoltrato regolarmente verso il ricevitore, con una segnalazione esplicita di congestione (a Livello 3).
L’indicazione di congestione può essere "riflessa", tramite opportuni bit nell’intestazione TCP, dal ricevitore alla sorgente, dando la possibilità a quest’ultima di modulare opportunamente la frequenza di emissione dei segmenti. Come si può notare, l’idea è analoga al Traffic Shaping adattativo nelle interfacce Frame Relay, dove la segnalazione della congestione avviene direttamente a Livello 2, tramite l’utilizzo dei bit FECN e BECN.
Il meccanismo ECN per avere effetto richiede una modifica del funzionamento del TCP, supportata ad oggi da tutte le principali implementazioni del TCP (Windows da Vista in poi, Linux, Unix BSD, MAC OS, iOS, ecc.). Per evitare che la controparte di una connessione TCP non supporti ECN, è necessario concordare tra gli end-point, durante la fase di three-way-handshake, l’utilizzo di ECN. Il meccanismo ECN è stato standardizzato nelle RFC 3168 - The Addition of Explicit Congestion Notification (ECN) to IP, del Settembre 2001.
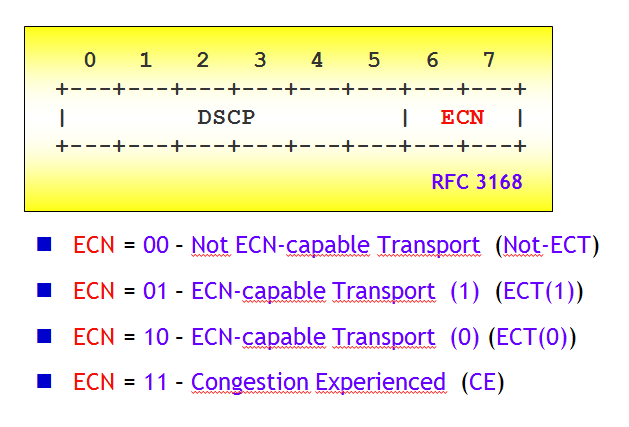
La segnalazione esplicita di congestione utilizza a Livello 3, i due bit inutilizzati nel byte TOS (Type Of Service) dell'intestazione IP, dopo la ridefinizione standardizzata nella RFC 2474, che, ricordo, riserva i primi 6 bit al campo DSCP (Differentiated Services Code Point). I due bit sono denominati, nella RFC 3168, campo ECN. Le quattro combinazioni dei due bit hanno il seguente significato:

Il meccanismo ECN è quasi sempre utilizzato congiuntamente all'algoritmo RED, e consente migliorarne le prestazioni nel senso che cerca di evitare, quando possibile, lo scarto dei pacchetti.

Illustrerò ora il tipico handshake in presenza del meccanismo ECN, riportato schematicamente nella figura seguente.

a <-- (1 - g)*a + g*F
dove g è una costante nell'intervallo (0, 1) e F il valore effettivo della frazione di pacchetti marcati durante la finestra precedente. L'aggiornamento avviene al termine di ogni finestra di dati (a occhio e croce, ogni RTT).
Nel lavoro originale citato sopra, scaricabile a questo link, potete trovare un modello analitico del DCTCP, con anche delle formule per la determinazione del valore di soglia K e del parametro g. In realtà quest'ultimo è di solito determinato su base sperimentale, piuttosto che sulla formula proposta. Ad esempio, nell'implementazione del DCTCP su Windows Server 2012, il valore di g è sempre preso pari a 1/16, determinato su base sperimentale.
I vantaggi del DCTCP sono un generale miglioramento di alcune delle problematiche esposte nella sezione precedente. In particolare vengono mitigati gli effetti negativi del Queue Buildup e del TCP incast, purché il numero dei worker non superi 35. Il DCTCP non introduce però vantaggi rispetto al problema della pseudocongestion.
Sono state proposte successivamente alcune varianti del DCTCP (es. ICTCP, IA-TCP, D2TCP, TCP-FITDC, TDCTCP, ecc.), ognuna con i suoi vantaggi e svantaggi. I più curiosi possono farsi un giro sul web per vedere le modifiche apportate.
CONCLUSIONI
Il DCTCP, proposto nel 2010, si è affermato velocemente ed è supportato dai principali Sistemi Operativi, come ad esempio Windows Server, Linux, Unix FreeBSD. Il suo utilizzo è attualmente limitato ad un ambiente Data Center, anche se vi sono studi in corso per valutarne l'applicazione sull'Internet. Nel caso in cui dall'interno del Data Center ci si colleghi a un server esterno sull'Internet, il DCTCP dovrebbe essere disabilitato. Non vi è al momento la possibilità di negoziarne l'applicazione da ambo i lati della connessione TCP, per cui questo processo va in qualche modo gestito manualmente via configurazione. Vi faccio notare che la storia non finisce qui. Oltre alle succitate varianti del DCTCP introdotte (e sono molte), un gruppo di ricercatori di Google ha proposto recentemente una nuova variante del TCP per l'utilizzo nei Data Center, in cui il segnale di congestione è il valore di RTT, stimabile con molta precisione con le NIC di nuova generazione. Magari ne parlerò in seguito.
Focalizziamo per il momento l'attenzione su cosa avviene alla ricezione del segnale di congestione. Il TCP "educatamente" reagisce diminuendo il ritmo di emissione dei segmenti e quindi lo aumenta, all'inizio in modo "aggressivo" (fase di Slow Start) poi in modo più blando (fase di Congestion Avoidance). Per fare questo, il TCP utilizza due variabili, la già citata finestra di congestione cnwd e una soglia SSTHRESH (Slow Start THRESHold), che segna il confine tra la fase di Slow Start e di Congestion Avoidance. A grandi linee questo è ciò che avviene:
- Alla ricezione del segnale di congestione (es. scadenza del TCP RTO o ricezione di tre TCP ACK duplicati), il TCP memorizza il valore di W attualmente utilizzato (NOTA: questo valore è indicato nella RFC 5681 come FlightSize). Sulla base di questo valore determina il valore di SSTHRESH. La RFC 5681 specifica un upper bound per SSTHRESH pari a max(FlightSize/2, 2*SMSS).
- Per i segmenti successivi utilizza un valore di W inferiore a SSTHRESH, in tal modo riducendo il ritmo di emissione dei segmenti.
- Il TCP inizia quindi ad aumentare il valore di W (in realtà aumenta il valore di cwnd), all'inizio in modo "aggressivo" (fase di Slow Start).
- Quando viene raggiunto un valore di W vicino a SSTHRESH, l'aumento diventa più blando (fase di Congestion Avoidance).
Quando cnwd' raggiunge il valore immediatamente inferiore a SSTHRESH, inizia la fase di Congestion Avoidance, dove la crescita di cnwd' diventa più blanda e, per ogni TCP ACK ricevuto segue la legge:
cnwd' <-- cnwd' + 1/cnwd'
Anche qui, è semplice dimostrare che ad ogni RTT la crescita di cnwd' è di tipo lineare:
cnwd' <-- cnwd' +1
La figura seguente riassume quanto fin qui detto.

Quella esposta è la versione originale di Van Jacobson del meccanismo di Congestion Avoidance, nota come TCP Tahoe. Delle altre versioni non parlerò, magari ci ritornerò in seguito con qualche altro post. Per trattare il DCTCP è sufficiente quanto esposto in questa sezione. A questo punto è ora di trattare il secondo argomento propedeutico.
EXPLICIT CONGESTION NOTIFICATION (ECN)
Come visto nella sezione precedente, la regolazione del traffico delle sessioni TCP avviene sulla base di un segnale di congestione "implicito" da parte della rete (es. la scadenza del TCP RTO (TCP Retransmission TimeOut), o la ricezione di tre TCP ACK duplicati consecutivi). Sulla base di questo segnale, il TCP entra nella fase di Slow Start e successivamente nella fase di Congestion Avoidance, riducendo di fatto drasticamente la frequenza di emissione dei segmenti, per poi aumentarla all'inizio in modo aggressivo, poi più gradualmente.
Esiste un algoritmo, il Random Early Detection (RED), che qualcuno chiama anche Random Early Discard o Random Early Drop, implementato da molto tempo nei router di tutti principali vendor, che sfrutta in modo intelligente questa proprietà del TCP, scartando in modo probabilistico pacchetti di applicazioni che utilizzano a livello di trasporto il TCP, al superamento di una prima soglia di guardia. (NOTA: per chi non conoscesse questo algoritmo, a questo link potete scaricare un estratto dalla mia documentazione sulla "QoS IP in ambiente Cisco", dove è tutto spiegato con dovizia di particolari).
Il meccanismo ECN ha lo scopo di migliorare il RED evitando, quando possibile, lo scarto dei pacchetti. L’idea del meccanismo ECN è quella di segnalare esplicitamente alla sorgente, tramite opportuni bit, la congestione di un buffer. Quindi, quando il RED decide, nella regione di scarto aleatorio, di scartare un pacchetto, la presenza del meccanismo ECN fa si che il pacchetto non venga scartato, ma inoltrato regolarmente verso il ricevitore, con una segnalazione esplicita di congestione (a Livello 3).
L’indicazione di congestione può essere "riflessa", tramite opportuni bit nell’intestazione TCP, dal ricevitore alla sorgente, dando la possibilità a quest’ultima di modulare opportunamente la frequenza di emissione dei segmenti. Come si può notare, l’idea è analoga al Traffic Shaping adattativo nelle interfacce Frame Relay, dove la segnalazione della congestione avviene direttamente a Livello 2, tramite l’utilizzo dei bit FECN e BECN.
Il meccanismo ECN per avere effetto richiede una modifica del funzionamento del TCP, supportata ad oggi da tutte le principali implementazioni del TCP (Windows da Vista in poi, Linux, Unix BSD, MAC OS, iOS, ecc.). Per evitare che la controparte di una connessione TCP non supporti ECN, è necessario concordare tra gli end-point, durante la fase di three-way-handshake, l’utilizzo di ECN. Il meccanismo ECN è stato standardizzato nelle RFC 3168 - The Addition of Explicit Congestion Notification (ECN) to IP, del Settembre 2001.
La segnalazione esplicita di congestione utilizza a Livello 3, i due bit inutilizzati nel byte TOS (Type Of Service) dell'intestazione IP, dopo la ridefinizione standardizzata nella RFC 2474, che, ricordo, riserva i primi 6 bit al campo DSCP (Differentiated Services Code Point). I due bit sono denominati, nella RFC 3168, campo ECN. Le quattro combinazioni dei due bit hanno il seguente significato:
- 00 – Not ECN-capable Transport : indica che il terminale che ha generato il pacchetto non utilizza ECN, e che quindi questo deve essere trattato dal RED (o eventualmente altro algoritmo di scarto) nel modo classico.
- 01 – ECN-capable Transport (1): scritto dalla sorgente per indicare che gli end-point della connessione TCP supportano il meccanismo ECN.
- 10 – ECN-capable Transport (0): Significato e utilizzo identici alla combinazione 01. E' quello consigliato dalla RFC 3168, per compatibilità con la vecchia RFC 2481.
- 11 – Congestion Experienced: indica uno stato di congestione di un buffer (possibile scarto determinato dal RED, o altro algoritmo).
Il meccanismo ECN è quasi sempre utilizzato congiuntamente all'algoritmo RED, e consente migliorarne le prestazioni nel senso che cerca di evitare, quando possibile, lo scarto dei pacchetti.
Il meccanismo ECN entra in funzione solo nella regione di scarto aleatorio, ossia la regione dove il RED decide di scartare casualmente i pacchetti. Gli eventi possibili a seguito della decisione del RED di scartare casualmente un pacchetto, sono i seguenti:
- Se la combinazione dei bit ECN è 01 (= ECT(1)) o 10 (= ECT(0)) , invece di essere scartato, il pacchetto viene inoltrato marcando i bit ECN con la combinazione 11 (= CE).
- Se la combinazione dei bit ECN è 00 (= Not-ECT), il pacchetto viene scartato (RED classico).
- Se la combinazione dei bit ECN è 11 (= CE), il pacchetto viene inoltrato senza alcuna modifica.
Nel caso in cui lo scarto deciso dal RED sia dovuto al superamento della soglia massima del RED, il meccanismo ECN non entra in funzione e il pacchetto viene scartato come nel RED classico.
L’implementazione pratica del meccanismo ECN ha senso solo se il TCP è in grado di reagire alla segnalazione esplicita di congestione. A tale scopo, la RFC 3168 ha standardizzato due dei 6 bit riservati presenti nei byte 13 e 14 dell’intestazione TCP (vedi figura seguente, tratta direttamente dalla RFC):
- Bit 8 : CWR (Congestion Window Reduced).
- Bit 9 : ECE (ECN-Echo).

Illustrerò ora il tipico handshake in presenza del meccanismo ECN, riportato schematicamente nella figura seguente.

- La sorgente invia i pacchetti IP con ECN = 01 (consigliato) o 10, per indicare che supporta il meccanismo ECN.
- Un router intermedio del percorso decide, sulla base di un qualche algoritmo (es. RED), di scartare un pacchetto. Il pacchetto non viene scartato ma inoltrato regolarmente con ECN = 11 (= CE).
- Al ricevitore arriva il pacchetto con ECN = 11, che segnala congestione in punto della rete.
- Il ricevitore invia una serie di TCP ACK con bit ECE = 1, fino a quando non riceve un segmento TCP con bit CWR = 1. Si noti che vengono inviati TCP ACK con ECE = 1 anche in risposta a segmenti TCP incapsulati in pacchetti IP con ECN = 01 o 10. Questo è necessario per l’affidabilità del procedimento.
- La sorgente alla ricezione dei TCP ACK, reagisce come nel caso di perdita entrando nella fase di Slow Start.
- Per segnalare al ricevitore che il bit ECE=1 è stato regolarmente rilevato, nel pacchetto successivo la sorgente invia il successivo segmento TCP con bit CWR=1.
Dopo queste necessarie e doverose premesse, è ora di passare all'argomento del post.
PROBLEMI DEL TCP (CLASSICO) NEI DATA CENTER
Sebbene il TCP sia stato costantemente aggiornato negli anni, il suo utilizzo nei moderni Data Center presenta ancora dei problemi importanti a causa delle peculiarità che questi hanno. In particolare, i problemi più sfidanti riguardano il meccanismo di Congestion Control illustrato sopra. Prima di vedere il funzionamento delle varianti proposte per migliorare il meccanismo di Congestion Control, quando il TCP viene utilizzato in ambito Data Center, è bene chiarire quali siano questi problemi, almeno quelli più importanti.

DATA CENTER TCP (DCTCP)
Sebbene il TCP sia stato costantemente aggiornato negli anni, il suo utilizzo nei moderni Data Center presenta ancora dei problemi importanti a causa delle peculiarità che questi hanno. In particolare, i problemi più sfidanti riguardano il meccanismo di Congestion Control illustrato sopra. Prima di vedere il funzionamento delle varianti proposte per migliorare il meccanismo di Congestion Control, quando il TCP viene utilizzato in ambito Data Center, è bene chiarire quali siano questi problemi, almeno quelli più importanti.
- TCP incast: il traffico incast è una tipologia di traffico many-to-one, molto comune nei moderni Data Center per i servizi Cloud. Molte applicazioni utilizzano infatti un modello di tipo Partition/Aggregate, dove un server principale (Aggregator) per completare il suo lavoro, richiede a un gruppo di worker, dei pezzetti elementari di lavoro, che combinati insieme consentono di completare il lavoro. Il problema con il traffico incast è che i worker rispondono in modo quasi "sincronizzato" alla richiesta dell'Aggregator, creando così in molti casi una situazione di congestione sul buffer condiviso dello switch o sul buffer associato alla porta dove è connesso l'Aggegator. E questo può accadere anche se i flussi di traffico elementari dei worker sono piccoli. Il risultato è che i worker entrano la fase di Slow Start e Congestion Avoidance in modo quasi sincronizzato, riproponendo lo stato di congestione. E poiché l'Aggregator ha un timeout, entro il quale se non riceve la risposta completa da un worker, non tiene conto del contributo di quel worker, il risultato è che il lavoro dell'Aggregator sarà incompleto, con effetti negativi sulla qualità percepita dagli utilizzatori (QoE, Quality of Experience). (NOTA: un fenomeno simile, noto come TCP Synchronization, avviene anche quando il buffer di una interfaccia utilizza una politica di scarto di tipo tail drop).

- Queue buildup: a causa della diversa natura delle applicazioni cloud, in un Data Center coesistono flussi di traffico piccoli e grandi (per questi sono spesso utilizzati i nomi curiosi di mice e elephant). I flussi di traffico molto grandi sono spesso di lunga durata e occupano molta banda, creando problemi ai flussi piccoli. I problemi creati sono di due tipi: il primo è una aumentata probabilità di perdita dei pacchetti, con conseguente riduzione del Throughput; il secondo è che, anche in assenza di perdita, aumenta di molto il ritardo di accodamento (queueing delay) a causa della crescita della coda (queue buildup), dovuta all'alta occupazione dei buffer da parte dei flussi elephant.
- Pseudocongestion: in Data Center virtualizzati, la virtualizzazione, come mostrato in vari studi eseguiti su Data Center di grandi dimensioni, porta a un deterioramento delle prestazioni sia del TCP che di UDP. Il Throughput diviene instabile e i ritardi end-to-end salgono, anche in caso di carichi moderati. La ragione sta nel funzionamento stesso dei server virtualizzati. Quando più Macchine Virtuali (VM, Virtual Machine) sono attive su uno stesso server fisico, il ritardo di scheduling introdotto dall'Hypervisor fa aumentare il tempo di attesa che ciascuna VM subisce per accedere a un processore del server. Il ritardo introdotto è altamente variabile e può variare da pochi microsecondi a parecchie centinaia di millisecondi, portando a ritardi di rete (es. RTT) difficilmente quantificabili, che influenzano negativamente il Throughput. Inoltre, questo ritardo potrebbe essere così alto, da far scattare la ritrasmissione dei segmenti TCP da parte delle VM, per scadenza del RTO (Retransmission TimeOut). E questo come noto viene visto dalle VM come un segnale di congestione, quando in realtà non vi è congestione. Per questa ragione, questo fenomeno è stato "battezzato" come pseudo-congestione.
DATA CENTER TCP (DCTCP)
Il DCTCP, a differenza delle altre versioni del TCP, si basa su una stima della persistenza dello stato di congestione. Sulla base di questa stima, qualora la congestione sia occasionale o abbia breve durata, la finestra cnwnd viene ridotta di poco, mentre in caso di congestione persistente, la finestra cnwnd viene dimezzata, come avviene per le versioni tradizionali del TCP. Il risultato è un notevole incremento del Throughput complessivo.
Il problema chiave è ovviamente come stimare la persistenza dello stato di congestione. Un'idea semplice potrebbe essere di contare quanti TCP ACK una sorgente riceve, con il bit ECE = 1. Purtroppo la versione originale del meccanismo ECN per questo non aiuta. Infatti, anche nel caso di congestione occasionale, come spiegato nel punto 4 nella sezione sopra dove ho illustrato il funzionamento dell'ECN, il ricevitore continua ad inviare TCP ACK con ECE = 1, anche in risposta a segmenti TCP incapsulati in pacchetti IP con ECN = 01 o 10, fino a quando non riceve un segmento TCP con bit CWR = 1. Questo è necessario per l’affidabilità del procedimento. Di conseguenza la sorgente di traffico, anche contando questi TCP ACK, non è in grado di distinguere se la congestione è persistente oppure occasionale. Questo perché il numero di TCP ACK con ECE = 1 inviati dal ricevitore alla sorgente, può essere di gran lunga superiore al numero di pacchetti effettivamente marcati con ECN = 11. La ragione alla base di tutto ciò è che il meccanismo ECN è stato progettato con il solo scopo di segnalare alla sorgente uno stato di congestione, senza curarsi se questo sia occasionale oppure persistente.
Per ovviare a questo problema, il DCTCP ha introdotto tre varianti, le prime due riguardanti il meccanismo ECN:
- I pacchetti vengono marcati con ECN = 11 in modo leggermente diverso rispetto al classico meccanismo RED. Il RED prevede due soglie e un profilo di marking probabilistico, basato su una stima dell'occupazione media del buffer (dettagli nel documento sul RED citato sopra, scaricabile a questo link). Nella variante utilizzata nel DCTCP, si usa invece una sola soglia K, e il marking con ECN = 11 avviene al superamento della soglia da parte dell'occupazione effettiva del buffer (e non di una sua stima, come avviene nel RED).
- Il meccanismo ECN viene modificato come segue: vengono inviati TCP ACK con ECE = 1 solo in risposta a pacchetti marcati con ECN = 11. In questo modo la sorgente è in grado di quantificare con ragionevole esattezza la persistenza dello stato di congestione. (NOTA: in presenza di Delayed ACK, questo meccanismo non funziona, per questo è stata introdotta una piccola variante. Per i più curiosi rimando direttamente al draft IETF citato sopra). Si noti che questa variante riduce l'affidabilità del segnale di congestione poiché nel caso di perdita di un TCP ACK con ECE = 1, la sorgente non viene informata dello stato di congestione, e quindi non riduce il suo ritmo di emissione dei segmenti TCP. Per la verità, essendo un Data Center gestito interamente da un singolo amministratore, e di solito con abbastanza banda disponibile, la probabilità di perdere un TCP ACK è abbastanza trascurabile.
- Alla ricezione di TCP ACK con ECE = 1, la finestra cnwnd viene ridotta seguendo la legge: cnwnd <-- cnwnd*(1 - a/2), dove a è una stima della frazione di pacchetti marcati con ECN = 11 (o di TCP ACK con ECE = 1).
Il valore di a viene stimato attraverso un classico algoritmo di exponential smoothing (identico a quello utilizzato dal RED per la stima dell'occupazione del buffer):
a <-- (1 - g)*a + g*F
dove g è una costante nell'intervallo (0, 1) e F il valore effettivo della frazione di pacchetti marcati durante la finestra precedente. L'aggiornamento avviene al termine di ogni finestra di dati (a occhio e croce, ogni RTT).
Nel lavoro originale citato sopra, scaricabile a questo link, potete trovare un modello analitico del DCTCP, con anche delle formule per la determinazione del valore di soglia K e del parametro g. In realtà quest'ultimo è di solito determinato su base sperimentale, piuttosto che sulla formula proposta. Ad esempio, nell'implementazione del DCTCP su Windows Server 2012, il valore di g è sempre preso pari a 1/16, determinato su base sperimentale.
I vantaggi del DCTCP sono un generale miglioramento di alcune delle problematiche esposte nella sezione precedente. In particolare vengono mitigati gli effetti negativi del Queue Buildup e del TCP incast, purché il numero dei worker non superi 35. Il DCTCP non introduce però vantaggi rispetto al problema della pseudocongestion.
Sono state proposte successivamente alcune varianti del DCTCP (es. ICTCP, IA-TCP, D2TCP, TCP-FITDC, TDCTCP, ecc.), ognuna con i suoi vantaggi e svantaggi. I più curiosi possono farsi un giro sul web per vedere le modifiche apportate.
CONCLUSIONI
Il DCTCP, proposto nel 2010, si è affermato velocemente ed è supportato dai principali Sistemi Operativi, come ad esempio Windows Server, Linux, Unix FreeBSD. Il suo utilizzo è attualmente limitato ad un ambiente Data Center, anche se vi sono studi in corso per valutarne l'applicazione sull'Internet. Nel caso in cui dall'interno del Data Center ci si colleghi a un server esterno sull'Internet, il DCTCP dovrebbe essere disabilitato. Non vi è al momento la possibilità di negoziarne l'applicazione da ambo i lati della connessione TCP, per cui questo processo va in qualche modo gestito manualmente via configurazione. Vi faccio notare che la storia non finisce qui. Oltre alle succitate varianti del DCTCP introdotte (e sono molte), un gruppo di ricercatori di Google ha proposto recentemente una nuova variante del TCP per l'utilizzo nei Data Center, in cui il segnale di congestione è il valore di RTT, stimabile con molta precisione con le NIC di nuova generazione. Magari ne parlerò in seguito.
Nessun commento:
Posta un commento