
Nella prima parte di questo post, disponibile a questo link, ho esposto alcune idee elementari su come sia possibile, con un po' di astuzia, eliminare il forwarding di Livello 2, senza toccare il "sacro graal" dell'implementazione corrente dello stack TCP/IP nei Sistemi Operativi, che sembra essere un tabù inattaccabile.
In questo seguito al post precedente, voglio toccare due aspetti:
- La mobilità degli Host, argomento molto importante nei Data Center odierni, dove le macchine virtuali (VM, anche indicate come workload) vengono spostate da un server ad un altro del Data Center vuoi per ottimizzare il carico dei server, vuoi per scaricare uno o più server (ad esempio, un intero rack) per motivi di manutenzione.
- L'assalto all'ultimo bastione: portare il routing a livello dei server.
MOBILITA' DEGLI HOST
E' abbastanza comune negli odierni Data Center di grandi dimensioni, spostare le VM da un server fisico ad un altro. Questo spostamento, al quale una nota Società di Software, leader nel mercato della virtualizzazione, ha affibbiato il nome vMotion, può essere di due tipi:
- Cold vMotion: è la modalità più semplice. Lo spostamento viene fatto a "macchina spenta", ossia senza mantenere attive eventuali sessioni di comunicazione. In altre parole, prima di spostare il workload da un server a un altro, si "spengono" tutte le applicazioni, che eventualmente si riaccendono una volta che il workload sia stato installato nel server destinazione.
- Hot vMotion: è la modalità più complessa. Lo spostamento viene fatto a "macchina accesa", mantenendo attive tutte le sessioni di comunicazione in atto. Il grosso problema è che questo spostamento va fatto nel più breve tempo possibile, pena la caduta delle sessioni, e potrebbe richiedere consistenti quantità di banda. Solo per fare un banale esempio, per spostare un workload di 4 Gbyte (= 32 Gbit) di RAM, su un link con banda di 10 Gbit/s, occorrono 3,2 secondi, un'eternità. Se si volessero spostare i workload di un intero server, che di VM ne ha ad esempio 40, utilizzando due link a 10 Gbit/s (configurazione abbastanza comune negli attuali Data Center), il tempo impiegato supererebbe il minuto (in condizioni ideali, si intende !).
Nell'Hot vMotion, per mantenere attive le sessioni di comunicazione, vi sono alcuni elementi che non possono cambiare:
- L'indirizzo IP della macchina virtuale (e questo è abbastanza ovvio).
- L'indirizzo MAC della macchina virtuale, altrimenti bisognerebbe aggiornare con qualche marchingegno (es. Gratuitous ARP) le ARP cache degli altri host della stessa subnet.
- Dopo lo spostamento, la macchina virtuale deve essere in grado di raggiungere il first-hop router e tutte le altre VM della stessa subnet, utilizzando i loro indirizzi MAC correnti. Questo perché lo spostamento Hot deve essere "invisibile" per la VM, in modo che questa non debba rideterminare la sua ARP cache.
Il problema dello spostamento viene oggi spesso risolto a Livello 2, spostando le VM all'interno di server appartenenti alla stessa VLAN (o VXLAN, in funzione del metodo di segmentazione utilizzato). In uno scenario evoluto VXLAN+EVPN, ampiamente trattato in post precedenti di questo blog, il procedimento a grandi linee è il seguente:
- L'Hypervisor del server di destinazione dello spostamento, rileva gli indirizzi MAC e/o IP della VM "in arrivo" (ad esempio, grazie a un Gratuituos ARP (es. Microsoft Hyper-V) o Reverse ARP (es. VMware) generato dalla VM).
- L'Hypervisor a sua volta propaga i messaggi GARP/RARP alla funzione VTEP, la quale, appresa la conoscenza del solo indirizzo MAC o della coppia <MAC, IP>, genera un messaggio Update BGP EVPN (di tipo 2), per annunciare l'indirizzo MAC o la coppia <MAC, IP>. Il messaggio contiene una Extended Community "MAC mobility" che altro non è che un numero di sequenza, aumentato di uno ad ogni spostamento (per i dettagli vedi questo post).
- A questo punto ciascuna funzione VTEP conoscerà la nuova localizzazione della macchina virtuale, e quindi sarà in grado di inoltrare traffico alla macchina virtuale nella nuova locazione.
Il vincolo posto da questa soluzione, come detto sopra, è che la macchina virtuale deve essere spostata all'interno dello stesso segmento VLAN o VXLAN, altrimenti andrebbe a finire su una subnet IP diversa e quindi, per i sacri princìpi della numerazione IP, non potrebbe mantenere lo stesso indirizzo IP.
Lavorando un po' di fantasia, ma non più di tanto, è possibile replicare questo modello a Livello 3. Pensate un attimo alla seguente sequenza di eventi:
- Ogni first-hop router (che ipotizzo essere virtuale all'interno di un Hypervisor) tiene traccia degli indirizzi IP degli Host (IP learning descritto nella prima parte di questo post).
- L'Hypervisor del server di destinazione dello spostamento, rileva l'indirizzo IP della macchina virtuale "in arrivo" e crea una Host-route (/32 in IPv4, /128 in IPv6) nella propria tabella di routing IP (o VRF nel caso di multi-tenancy).
- L'Host-route viene redistribuita in un protocollo di routing (es. BGP), consentendo così a ciascun router della rete di avere un percorso verso la nuova "locazione" della macchina virtuale.
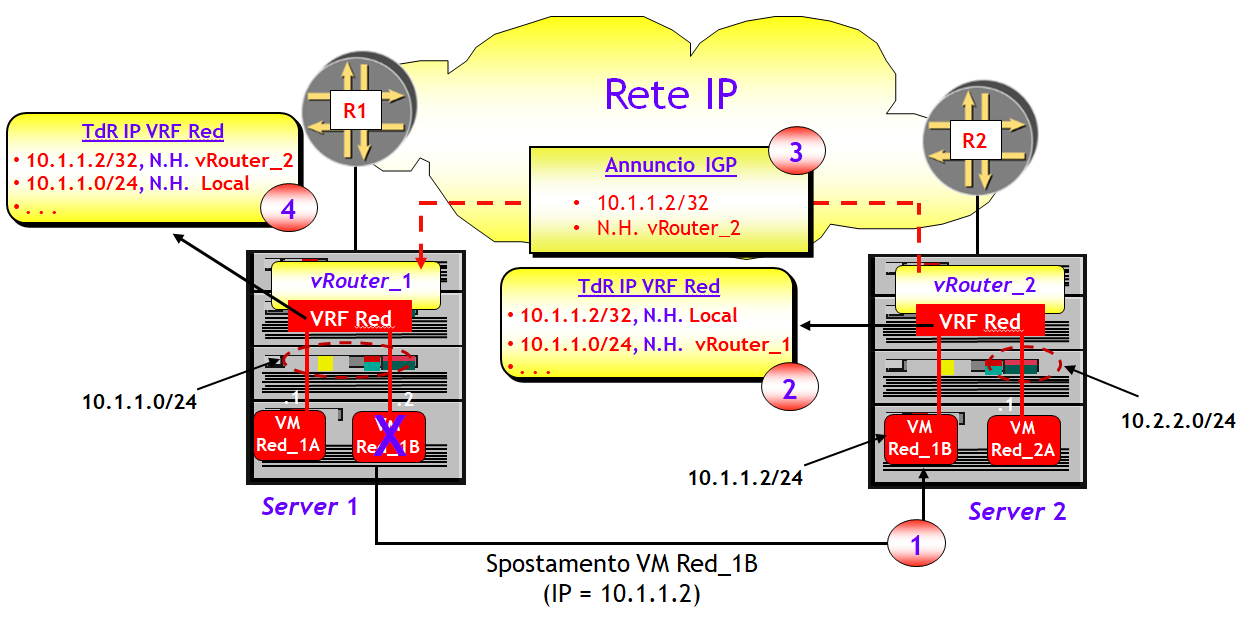
La VM Red_1B viene spostata dal server 1 al server 2, eventualmente, nel caso di multi-tenancy, all'interno della VRF dello stesso tenant (passo 1 nella figura). Indipendentemente dalle subnet IP utilizzate, l'indirizzo IP della VM spostata (= 10.1.1.2 nella figura) viene considerato dal first-hop router sul server 2 (= vRouter_2) come una Host-route (= 10.1.1.2/32), che installa nella propria tabella di routing IP. La tabella di routing IP del vRouter_2 avrà quindi, oltre alla subnet IP 10.1.1.0/24, anche la Host-route (locale) 10.1.1.2/32 (passo 2 nella figura). La Host-route viene quindi annunciata attraverso un qualsiasi protocollo IGP (es. iBGP) agli altri vRouter (passo 3 nella figura), che alla ricezione dell'annuncio installeranno la Host-route nella propria tabella di routing IP (passo 4 della figura. E questo è il piano di controllo. Veniamo ora al piano dati.
Supponiamo che una qualsiasi VM, ad esempio la VM Red_1A, voglia inviare un pacchetto IP alla VM "spostata" Red_1B. Anche qui, per non toccare il "sacro graal" dell'implementazione corrente dello stack TCP/IP nei Sistemi Operativi, utilizzerò lato VM il protocollo ARP nel modo classico. Poiché l'indirizzo IP destinazione (= 10.1.1.2) appartiene alla stessa subnet IP a cui appartiene la VM Red_1A (che ha indirizzo IP 10.1.1.1/24), la VM Red_1A invia un ARP request per risolvere l'indirizzo IP 10.1.1.2. Supponiamo che il vRouter_1 sia configurato a rispondere, come visto nel post precedente, con un MAC fittizio (Anycast MAC Gateway, AMG). Ora tutto procede come visto nel post precedente. L'indirizzo AMG viene interpretato dal vRouter_1 come "esegui un lookup sulla Tabella di Routing IP". A questo punto, grazie al principio del Longest Match Prefix, il vRouter_1 utilizza per il forwarding l'informazione relativa alla riga 10.1.1.2/32. E qui finisce (quasi) la storia. Quello che manca è l'incapsulamento che consenta di garantire che il pacchetto non vada a finire al di fuori della propria VPN, ma questo l'ho trattato varie volte in questo blog (es. MPLSoverIP/UDP/GRE/MPLS, VXLAN, NVGRE, STT, ecc.).
Qualcuno potrebbe obiettare, e si tutto bello ma assolutamente non scalabile, come si fa a mantenere in memoria tutte queste host-route ? E allora vi faccio una domanda, occupa più memoria una riga di una tabella MAC o una riga di una host-route su una tabella di routing ? E' più scalabile mantenere una MAC table con centinaia di migliaia di indirizzi MAC oppure, in alternativa una tabella di routing IP con centinaia di migliaia di host-route ? La risposta è molto semplice e ve la lascio come punto di meditazione. E non dimenticate che le host-route possono essere aggregate e gli indirizzi MAC no !
E ora la parte triste della storia ... Quella che ho esposto non è una novità, ma fu proposta da Cisco nei primi anni 2000 con il nome di Local Area Mobility. Non ebbe seguito per due motivi, il primo è che il codice per realizzare questo modello di mobilità pare non fosse molto stabile, il secondo (e qui c'è una discreta colpa degli Zeloti del Livello 3) è che va a violare un principio ritenuto "sacro" come il fatto che un host non può avere un indirizzo IP non appartenente alla subnet IP con cui è numerato il segmento di rete (LAN) dove l'host è collegato. Comunque, per i più curiosi, leggetevi questo articoletto che ho scaricato da qualche parte del web, è tutto scritto lì, con tanto di esempio pratico e relative configurazioni.
ROUTING NEI SERVER
Ho citato in molti post passati che la tendenza dei moderni Data Center è di utilizzare IP fabric, confinando il Livello 2 solo a livello di server. Anche con una IP fabric, nel caso frequente di server con collegamenti ridondati, vedi figura seguente, è comune utilizzare nei server tecniche di Livello 2 come MLAG, per realizzare collegamenti aggregati verso gli switch (o meglio, router !) Leaf (un classico esempio è la funzionalità vPC (virtual Port Channel) dei Nexus Cisco).

Tecniche come MLAG hanno però delle limitazioni, come ad esempio:
- Tipicamente sono tecniche proprietarie, non esiste alcuna procedura standard.
- Sono limitate a una ridondanza a due link, che limita la banda disponibile in caso di fuori servizio di uno dei due link o di uno dei due switch Leaf.
- Tipicamente, nelle implementazioni correnti (vedi vPC Cisco), sono necessari almeno due collegamenti extra inter-switch per il piano di controllo intra-MLAG, riducendo il numero di porte a disposizione per i server sugli switch Leaf.
Implementare il routing direttamente a livello di server elimina tutte le problematiche relative all'utilizzo di MLAG descritte sopra, fornendo maggiore ridondanza con la possibilità di avere più di due collegamenti uplink da server a switch Leaf ed eliminando la necessità di collegamenti inter-switch.

Anche per le applicazioni che ancora hanno bisogno del Livello 2, portare il routing nei server ha ancora senso. Per queste infatti spesso si utilizzano segmenti VXLAN, e ipotizzando la funzione VTEP nell'Hypervisor del server, l'indirizzo IP della VTEP può essere annunciato direttamente dal protocollo di routing del server. Questo tra l'altro consentirebbe maggiore ridondanza sia a livello di link di collegamento, il numero può essere maggiore di due, che a livello di server, utilizzando indirizzi anycast.
Quest'ultima soluzione, che consiste nell'assegnare a server diversi uno stesso indirizzo IP /32 (o /128 in IPv6), consente anche di facilitare il Load Balancing. Infatti, assegnando lo stesso indirizzo IP a più server e annunciando questo indirizzo IP nel dominio di routing (dominio che comprende anche la IP Fabric !), si ottengono più percorsi verso la stessa destinazione anycast. Ciascuno switch ha quindi più percorsi disponibili verso lo stesso indirizzo IP, che possono essere eventualmente utilizzati in Load Balancing, distribuendo così il carico di lavoro su più server. Ovviamente, su ciascun server con lo stesso indirizzo IP anycast dovrebbero "girare" le stesse applicazioni o servizi. Ad esempio, NTP e DNS sono due popolari applicazioni che utilizzano questa tecnica.
Introdurre il routing nei server semplifica inoltre tutte le procedure di mobilità delle VM trattate nella sezione precedente, poiché consente di disaccoppiare i server dai propri rack, aggiungendo notevole flessibilità alla loro dislocazione. I server possono essere dislocati in qualsiasi rack all'interno del Data Center, essendo raggiungibili con il medesimo indirizzo IP, senza necessità di alcun cambio di configurazione.
Infine, un ulteriore vantaggio (ma potrei continuare), è la possibilità di utilizzare, nel caso di "manutenzione" di uno switch, le tecniche di graceful shutdown tipiche del Livello 3, che consentono un rerouting del traffico evitando lo switch su cui operare.
CONCLUSIONI
Questo post chiude il cerchio sulle mie provocazioni (non solo mie per la verità) circa l'inutilità del Livello 2 come metodologia di forwarding. Come ho affermato più volte, il Livello 2 a mio modesto parere dovrebbe fare il Livello 2 secondo i canoni classici del modello ISO/OSI, che non contemplano che si occupi di forwarding. Ma il mondo del networking è stato sottoposto ad un ampio lavaggio del cervello da parte dei principali vendor di apparati, che ci hanno fatto credere, per vendere più roba, che il mondo funziona così. Con risultati a dir poco discutibili. L'invito che faccio sempre ai miei studenti, e che umilmente faccio a voi affezionati lettori di questo blog, è di pensare con la propria testa, e di non farvi guidare dalle teorie dei vendor. E se il vostro vendor preferito insiste con le sue idee, valutate criticamente se sono idonee, e se le soluzioni proposte sono le migliore dal punto di vista costi/prestazioni. Altrimenti cambiate vendor, e vi posso garantire che ce sono alcuni molto smart sul mercato, che seguono le idee che vi ho esposto (non faccio nomi per evitare qualsiasi tipo di pubblicità).
Voglio concludere con una frase che ho letto in un vecchio post del mio amico Ivan Pepelnjak, nonché una delle migliori menti del networking mondiale, che riflette quanto appena affermato:
It’s infinitely sad to watch all the networking vendors running around like headless chickens trying to promote yet-another fabric routing at layer-2 solution, instead of stepping back and solving the problem where it should have been solved: within layer 3.
Nessun commento:
Posta un commento